[TOC]
concurrent并发包
我们进行多线程编程,无非是要达到几个目的:
- 利用多线程提高程序的扩展能力,以达到业务对吞吐量的要求
- 协调线程间调度、交互、以完成业务逻辑
- 线程间传递数据和状态,这同样是实现业务逻辑的需要
对于并发包主要分为同步工具,线程安全容器,并发队列以及Executor框架,对于这些了解,应该做到
- 理解具体设计,实现和能力
- 深入掌握这些工具的适用场景,用法甚至原理。能够熟练写出典型代码
代替synchronized的高级同步工具
包括CountDownLatch、CyclicBarrier、Semaphore等,可以实现更加丰富的多线程操作,比如利用Semaphore作为资源控制器,限制同时进行工作的线程的数量
CountDownLatch
闭锁,相当于一扇门,在达到结束状态之前,这扇门一直是关闭的,所有线程都无法进入,到达结束状态之后,这扇门就会打开,所有线程都可以进入;后面不会再关闭;
适用场景
- 确保某个计算在其所有需要的资源都初始化后才能继续执行
- 服务依赖于其他所有服务都启动之后才能够启动
- 等待操作的所有执行者都准备完毕之后,再继续执行
使用例子
模拟一个服务启动时需要等待其他资源初始线程执行完毕后,才能启动
public class ServiceInit {
private CountDownLatch countDownLatch;
public ServiceInit(CountDownLatch countDownLatch){
this.countDownLatch = countDownLatch;
}
public void init() throws InterruptedException {
System.out.println("begin to wait resource");
countDownLatch.await();//等待资源准备完成
System.out.println("resource prepare down");
}
public static void main(String[] args){
CountDownLatch countDownLatch = new CountDownLatch(4);
ServiceInit serviceInit = new ServiceInit(countDownLatch);
ConfigResource configResource1 = new ConfigResource(countDownLatch,"config-1");
ConfigResource configResource2 = new ConfigResource(countDownLatch,"config-2");
ConnectResource connectResource1 = new ConnectResource(countDownLatch,"connect-1");
ConnectResource connectResource2 = new ConnectResource(countDownLatch,"connect-2");
MyThreadPoolExecutor executor = new MyThreadPoolExecutor();
//启动服务
executor.execute(()->{
try {
serviceInit.init();
}catch (Exception e){
System.out.println(e);
}
});
//服务运行前资源准备
executor.execute(configResource1);
executor.execute(configResource2);
executor.execute(connectResource1);
executor.execute(connectResource2);
executor.shutdown();
}
}
abstract class ServiceResource implements Runnable{
protected CountDownLatch countDownLatch;
protected String resourceName;
public ServiceResource(CountDownLatch countDownLatch,String name){
this.resourceName = name;
this.countDownLatch = countDownLatch;
}
public void done() {
countDownLatch.countDown();
}
abstract void init() throws InterruptedException;
@Override
public void run() {
try {
init();
}catch (Exception e){
System.out.println(e);
}
}
}
class ConfigResource extends ServiceResource{
public ConfigResource(CountDownLatch countDownLatch, String name) {
super(countDownLatch, name);
}
@Override
public void init() throws InterruptedException {
System.out.println("init ConfigResource "+resourceName);
Thread.sleep(1000L);
done();
}
}
class ConnectResource extends ServiceResource{
public ConnectResource(CountDownLatch countDownLatch, String name) {
super(countDownLatch, name);
}
@Override
public void init() throws InterruptedException {
System.out.println("init ConnectResource "+resourceName);
Thread.sleep(1000L);
done();
}
}
实现原理
它的状态包括一个计数器,初始化为一个正数,表示需要等待的事件数量。countDown()递减计数器,表示一个事件已经完成,而await()表示等待计数器为0;
底层同步机制实现是依靠AQS,计数器状态值同样是利用的AQS状态值;
直接看countDownLatch中关于AQS的实现
private static final class Sync extends AbstractQueuedSynchronizer {
private static final long serialVersionUID = 4982264981922014374L;
//初始化时直接调用AQS设置状态值
Sync(int count) {
setState(count);
}
int getCount() {
return getState();
}
//调用await之后,会调用该方法,判断是否能获取成功,这里就是判断当前状态值是否0。
protected int tryAcquireShared(int acquires) {
return (getState() == 0) ? 1 : -1;
}
//在调用countDown方法后,会调用该方法,将状态值-1,如果状态值不为0,则返回false,AQS不唤醒阻塞的线程,为0时释放锁,唤醒阻塞线程
protected boolean tryReleaseShared(int releases) {
// Decrement count; signal when transition to zero
for (;;) {
int c = getState();
if (c == 0)
return false;
int nextc = c-1;
if (compareAndSetState(c, nextc))
return nextc == 0;
}
}
}
Semaphore
信号量;它允许通过控制一定数量的permit,来达到限制资源访问的目的。他有公平和非公平两种模式,公平信号量保证FIFO的顺序给予请求的线程,而非公平则不一定,当请求的线程能够请求成功时,可以进行插队。
适用场景
- 控制某个特定资源的操作数量
- 用来实现某种资源池,比如连接池
- 对容器施加边界
使用例子
有限容器类,对于添加超过容器限制的线程,将进行阻塞;
public class BoundedHashSet<T> {
private final Set<T> set;
private final Semaphore sem;
public BoundedHashSet(int bound){
this.set = Collections.synchronizedSet(new HashSet<>());
this.sem = new Semaphore(bound);
}
public boolean add(T o) throws InterruptedException{
sem.acquire();
boolean wasAdded = false;
try {
wasAdded = set.add(o);
return wasAdded;
}finally {
if(!wasAdded){
sem.release();
}
}
}
public boolean remove(Object o){
boolean wasRemoved = set.remove(o);
if (wasRemoved){
sem.release();
}
return wasRemoved;
}
}
实现原理
信号量内部状态也是一个计数器,初始化一个整数值,表示可申请的数量。需要的时候调用acquire()成功的话,信号量-1,如果信号量为0,则阻塞当前线程。线程任务完成之后,调用release()释放,信号量+1 同样看看Semaphore的AQS实现
abstract static class Sync extends AbstractQueuedSynchronizer {
private static final long serialVersionUID = 1192457210091910933L;
//初始化设置状态值
Sync(int permits) {
setState(permits);
}
final int getPermits() {
return getState();
}
//非公平方式设置状态值,先尝试能否获取,不能获取在返回<0,交由AQS去阻塞当前线程
final int nonfairTryAcquireShared(int acquires) {
for (;;) {
int available = getState();
int remaining = available - acquires;
if (remaining < 0 ||
compareAndSetState(available, remaining))
return remaining;
}
}
//两种类型释放都是直接状态值+1
protected final boolean tryReleaseShared(int releases) {
for (;;) {
int current = getState();
int next = current + releases;
if (next < current) // overflow
throw new Error("Maximum permit count exceeded");
if (compareAndSetState(current, next))
return true;
}
}
//资源总数减去目标值
final void reducePermits(int reductions) {
for (;;) {
int current = getState();
int next = current - reductions;
if (next > current) // underflow
throw new Error("Permit count underflow");
if (compareAndSetState(current, next))
return;
}
}
//清空资源数
final int drainPermits() {
for (;;) {
int current = getState();
if (current == 0 || compareAndSetState(current, 0))
return current;
}
}
}
static final class FairSync extends Sync {
private static final long serialVersionUID = 2014338818796000944L;
FairSync(int permits) {
super(permits);
}
//公平的方式就一定会判断,前面是否有正在等待资源的线程,有就不设置,直接返回-1;
protected int tryAcquireShared(int acquires) {
for (;;) {
if (hasQueuedPredecessors())
return -1;
int available = getState();
int remaining = available - acquires;
if (remaining < 0 ||
compareAndSetState(available, remaining))
return remaining;
}
}
}
CyclicBarrier
CyclicBarrier 与闭锁类似,但是闭锁用于等待事件全部完全后放行,而栅栏阻塞一组线程;
当线程执行到某个位置时,调用await()阻塞,直到有特定数量的线程都到达后,栅栏打开,放行一组线程后重置以便下次使用。如果对await()的调用超时,或者await阻塞的线程被中断,那么栅栏就会被认为是打破了,所有阻塞的await调用都将终止并抛出BrokenBarrierException。
栅栏的构造函数还可以将一个栅栏的操作传递给它,这是一个runnable,当指定数量的线程阻塞之后,会先执行该方法,然后再放行。
可以使一定数量的参与方反复地在栅栏位置汇集;
适用场景
- 并行迭代算法中很有用,将一个问题拆分成多个子问题。
使用例子
public class CyclicBarrierSample {
public static void main(String[] args) throws InterruptedException {
CyclicBarrier barrier = new CyclicBarrier(5, new Runnable() {
@Override
public void run() {
System.out.println("Action...GO again!");
}
});
for (int i = 0; i < 5; i++) {
Thread t = new Thread(new CyclicWorker(barrier));
t.start();
}
}
static class CyclicWorker implements Runnable {
private CyclicBarrier barrier;
public CyclicWorker(CyclicBarrier barrier) {
this.barrier = barrier;
}
@Override
public void run() {
try {
for (int i=0; i<3 ; i++){
System.out.println("Executed!");
barrier.await();
}
} catch (BrokenBarrierException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
实现原理
内部有一个int值 parties,初始化时传入的数字即是这个歌值,用来表示需要阻塞的线程数量。除此之外主要使用ReentrantLock和Condition来实现对阻塞数量状态值的同步更新数线程阻塞。
先看await()的主要逻辑
/**
* Main barrier code, covering the various policies.
*/
private int dowait(boolean timed, long nanos)
throws InterruptedException, BrokenBarrierException,
TimeoutException {
final ReentrantLock lock = this.lock;
lock.lock(); //上锁
try {
final Generation g = generation;
//这里主要判断当前栅栏是否被破坏,是的话直接返回异常
if (g.broken)
throw new BrokenBarrierException();
if (Thread.interrupted()) {
breakBarrier();
throw new InterruptedException();
}
int index = --count;
if (index == 0) { // tripped
boolean ranAction = false;
try {
//这里直接先执行构造函数传入的runnable
final Runnable command = barrierCommand;
if (command != null)
command.run();
ranAction = true;
//这里面主要就是调用Condition的signalAll()唤醒所有线程,并且重置count;
nextGeneration();
return 0;
} finally {
if (!ranAction)
breakBarrier();
}
}
// loop until tripped, broken, interrupted, or timed out
for (;;) {
try {
if (!timed)
trip.await();//这里就是Condition的await()方法,阻塞当前线程
else if (nanos > 0L)
nanos = trip.awaitNanos(nanos);
} catch (InterruptedException ie) {
if (g == generation && ! g.broken) {
breakBarrier();
throw ie;
} else {
// We're about to finish waiting even if we had not
// been interrupted, so this interrupt is deemed to
// "belong" to subsequent execution.
Thread.currentThread().interrupt();
}
}
if (g.broken)
throw new BrokenBarrierException();
if (g != generation)
return index;
if (timed && nanos <= 0L) {
breakBarrier();
throw new TimeoutException();
}
}
} finally {
lock.unlock();
}
}
处理常用的await()方法,还有await(long timeout,TimeUnit unit)方法来指定规定时间内阻塞,已经getNumberWaiting来获取当前阻塞的线程数量。
线程安全容器
比如最常见的ConcurrentHashMap、有序的ConcurrentSkipListMap,或者通过类似快照机制,实现线程安全的动态数组CopyOnWriteArrayList等。
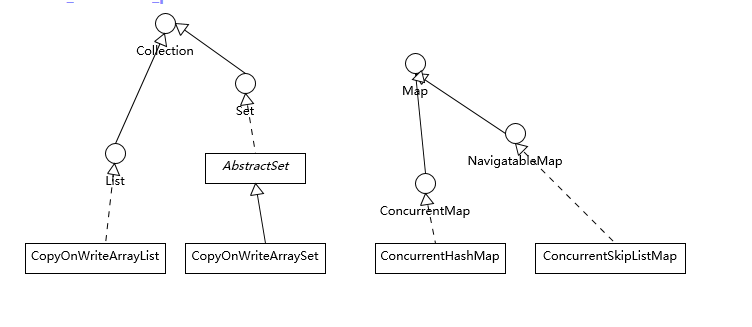
为什么没有没有ConcurrentTreeMap,因为要实现高效的线程安全是非常困难的,它的实现基于复杂的红黑树。为保证访问效率,当我们插入或删除节点时,会移动节点进行平衡操作,这导致在并发场景中难以进行合理粒度的同步
ConcurrentHashMap
侧重于 Map 放入或者获取的速度,而不在乎顺序,大多推荐使用 ConcurrentHashMap
ConcurrentHashMap在1.8之后,不在使用分段锁,而是直接用CAS + synchronized以及Volatile来保证线程安全,在put的时候,会先求出hash值,然后找到对应的槽,如果该槽为null,则会使用CAS将当前值设为该槽的节点,如果不为null,则会锁住该槽,然后对该槽进行插入操作。
而get则不要任何同步操作,因为ConcurrentHashMap中get操作涉及的遍历,比如tab,已经tab中的Node,Node中的value都被修饰为volatile,所以put中的所有最新操作对于get来说都是可见的。
ConcurrentSkipListMap
侧重于顺序 ,而不在乎放入或者获取的速度,大多推荐使用 ConcurrentSkipListMap;如果我们需要对大量数据进行非常频繁地修改,ConcurrentSkipListMap 也可能表现出优势。
CopyOnWriteArrayList
任何修改操作,如 add、set、remove,都会拷贝原数组,修改后替换原来的数组,通过这种防御性的方式,实现另类的线程安全;
public boolean add(E e) {
synchronized (lock) {
Object[] elements = getArray();
int len = elements.length;
// 拷贝
Object[] newElements = Arrays.copyOf(elements, len + 1);
newElements[len] = e;
// 替换
setArray(newElements);
return true;
}
}
final void setArray(Object[] a) {
array = a;
}
所以这种容器比较适合在读多写少的场景,否则写的开销有点大。
CopyOnWriteArraySet
CopyOnWriteArraySet 是通过包装了 CopyOnWriteArrayList 来实现的
并发队列
如各种BlockingQueue实现,比较典型的ArrayBlockingQueue,SynchronousQueue或针对特定场景的PriorityBlockingQueue等
ArrayBlockingQueue
底层存储为数组的有界阻塞队列。当队列满时尝试添加会阻塞线程,队列为空是尝试获取也会阻塞线程,有公平和非公平两种方式
适用场景
- 由于基于数组,容量固定所以不容易出现内存占用率过高
- 如果容量太小,取数据比存数据的速度慢,那么会造成过多的线程进入阻塞(也可以使用offer()方法达到不阻塞线程)
- 由于存取共用一把锁,所以有高并发和吞吐量的要求情况下,不建议使用ArrayBlockingQueue。
- 使用场景更多应该放在项目的一些次级业务中
原理
这里是借助Condition来实现的,主要有以下两个,notEmpty和notFull条件变量,当检测到当前队列已经满了之后,就调用notFull.await();阻塞当前线程直到有消费者消费之后调用notFull.signal();;notEmpty同理;
/** Condition for waiting takes */
private final Condition notEmpty;
/** Condition for waiting puts */
private final Condition notFull;
其他的操作都会使用ReentrantLock一把锁锁住。
LinkedBlockingQueue
LinkedBlockingQueue基于链表实现,队列容量默认Integer.MAX_VALUE,当然也可以指定大小。
存/取数据的操作分别拥有独立的锁,可实现存/取并行执行。
通常相比与数组的实现,他的吞吐量会更好,但是性能表现更差。
适用场景
- 基于链表,数据的新增和移除速度比数组快,但是每次存储/取出数据都会有Node对象的新建和移除,所以也存在由于GC影响性能的可能
- 默认容量非常大,所以存储数据的线程基本不会阻塞,但是如果消费速度过低,内存占用可能会飙升。
- 读/取操作锁分离,所以适合有并发和吞吐量要求的项目中
- 在项目的一些核心业务且生产和消费速度相似的场景中
原理
直接看源代码,从锁和Condition的结构可以看出,Condition分为notEmpty和notFull,这两个与ArrayBlockingQueue一样,区别于ArrayBlockingQueue的是他使用了takeLock和putLock,分别用于添加和移除。所以锁的粒度更小。
/** Lock held by take, poll, etc */
private final ReentrantLock takeLock = new ReentrantLock();
/** Wait queue for waiting takes */
private final Condition notEmpty = takeLock.newCondition();
/** Lock held by put, offer, etc */
private final ReentrantLock putLock = new ReentrantLock();
/** Wait queue for waiting puts */
private final Condition notFull = putLock.newCondition();
SynchronousQueue
采用双栈双队列算法的无空间队列或栈,没有容量,是无缓冲等待队列,是一个不存储元素的阻塞队列,只有消费者没有生产者,消费者阻塞,只有生产者没有消费者,生产者阻塞。
使用场景
- 轻量级别的任务转交
- 两个线程之间同步共享变量
- 两个或者多个线程之间进行同步
PriorityBlockingQueue
优先同步阻塞队列。
Executor框架
An object that executes submitted Runnable tasks. This interface provides a way of decoupling task submission from the mechanics of how each task will be run, including details of thread use, scheduling, etc. An Executor is normally used instead of explicitly creating threads. 执行提交的Runnable任务的对象。这个接口提供了一种将任务提交与如何运行每个任务的机制,包括线程的详细信息使用、调度等。通常使用Executor而不是显式地创建线程。
Executor是一个线程池框架,在开发中如果需要创建线程可以优先考虑使用Executor,无论是单线程还是多线程,Executor提供了很多有用的功能,比如线程状态和生命周期的管理 。
在了解之前,说说为什么需要线程池?
- 管理线程的生命周期开销非常高。
- 线程间上下文切换造成大量资源浪费
- 程序稳定性。一台机器的线程数量往往都是有限制的,可能受诸如底层操作系统,jvm等限制,这可能导致整个程序不可用。
Executor框架结构
大体分为三个主要部分
- 任务。工作单元,主要为Runnable和Callable接口
- 任务执行。把任务分配给多个线程执行的机制。包括Executor及继承紫Executor接口的ExecutorService接口
- 异步计算结果。包括Future接口以实现了Future接口的FutureTask类
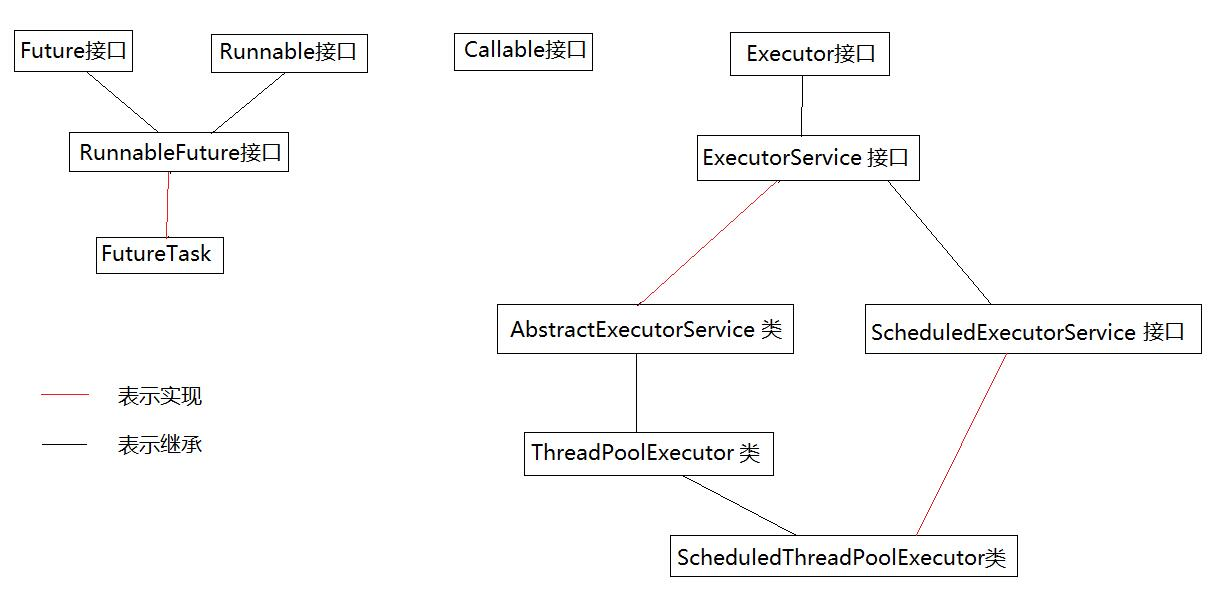
executor: 单说executor个接口,他提供了一个方法executor,这个方法接受一个Runnable,返回void,这个方法旨在表达,将任务执行和任务提交解耦,我们调用该方法,将我们任务提交出去,但是任务具体怎么执行,何时执行交由Executor框架实现下的具体执行器调度执行。
ExecutorService: 该接口继承Executor接口,添加了shutdown,shutdownNow,submit,inveAll等接口,submit方法来拓展execute方法,返回表示该任务的future;shutdown用来停止线程池执行任务,有立即停止和平滑的停止。
AbstractExecutorService:ExecutorService的抽象实现类,提供某些方法的默认实现。
ThreadPoolExecutor:Executor最核心的类,继承AbstractExecutorService抽象类,主要功能是创建线程池,给任务分配线程资源,执行任务
ScheduledExecutorSerivce 和 ScheduledThreadPoolExecutor: 提供了另一种线程池:延迟执行和周期性执行的线程池。
Executors:这是一个静态工厂类,该类定义了一系列静态工厂方法,通过这些工厂方法可以返回各种不同的线程池
ThreadPoolExecutor
主要线程池的实现,基于该类,利用Executors工厂来创建SingleThreadExecutor,FixedThreadPool,CachedThreadPool,ScheduledExecutor这几种线程池; 它的构造设计以下关键参数
- corePoolSize:线程池要持有的线程数量,即使是空闲的线程。除非设置了allowCoreThreadTimeOut为true(该值默认为false),超过keepAliveTime等待时长,core数量内的线程也会被回收
- maximumPoolSize:该线程池最大可以同时存在的线程数
- keepAliveTime:当持有的线程数量大于corePollSize时,这是多余空闲线程在终止前等待新任务的最长时间。
- unit: keepAliveTime参数的时间单位
- BlockingQueue
workQueue:用于在执行任务之前保存任务的队列,保存的是提交的Runnable - ThreadFactory threadFactory:执行创建新线程的工厂
- RejectedExecutionHandler handler:执行被阻塞时使用的处理程序,因为达到了线程边界和队列容量
SingleThreadExecutor
此线程池 Executor 只有一个线程。它用于以顺序方式的形式执行任务。如果此线程在执行任务时因异常而挂掉,则会创建一个新线程来替换此线程,后续任务将在新线程中执行。
ExecutorService executorService = Executors.newSingleThreadExecutor()
实现原理
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1,
1,
0L,
TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
core线程数为1,最大池子线程数也为1,所以始终只有一个线程,使用LinkedBlockingQueue队列来保存任务。
适用场景
适用于需要保证顺序地执行各个任务;并且在任意时间点,不会有多个线程是活动的场景
FixedThreadPool(n)
顾名思义,它是一个拥有固定数量线程的线程池。提交给 Executor 的任务由固定的 n 个线程执行,如果有更多的任务,它们存储在 LinkedBlockingQueue 里。这个数字 n 通常跟底层处理器支持的线程总数有关。
ExecutorService executorService = Executors.newFixedThreadPool(4);
实现原理
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
core和max线程数都为指定的线程数量,空闲等待时长为0秒(因为如果不开启allowCoreThreadTimeOut,他就只是针对超过core数量的线程,这里不会由超过core数量的线程,所以设置了也没有意义)。队列使用LinkedBlockingQueue。
适用场景
FixedThreadPool适用于为了满足资源管理的需求,而需要限制当前线程数量的应用场景,它适用于负载比较重的服务器
CachedThreadPool
该线程池主要用于执行大量短期并行任务的场景。与固定线程池不同,此线程池的线程数不受限制。如果所有的线程都在忙于执行任务并且又有新的任务到来了,这个线程池将创建一个新的线程并将其提交到 Executor。只要其中一个线程变为空闲,它就会执行新的任务。 如果一个线程有 60 秒的时间都是空闲的,它们将被结束生命周期并从缓存中删除。
但是,如果管理得不合理,或者任务不是很短的,则线程池将包含大量的活动线程。这可能导致资源紊乱并因此导致性能下降。
ExecutorService executorService = Executors.newCachedThreadPool();
实现原理
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
core数量为0,最大线程数为Integer.MAX_VALUE,空闲线程等待时长最长为60s,所以该线程池极端情况下可以创建MAX_VALUE个线程。队列使用的是SynchronusQueue,空闲的线程会一直poll阻塞等待任务提交,而有新任务过来,加入队列中后会立即被消费执行,如果没有空闲线程则会创建新线程来理解执行。
适用场景
CachedThreadPool是大小无界的线程池,适用于执行很多的短期异步任务的小程序,或者是负载较轻的服务器。
ScheduledExecutor
它主要用来在给定的延迟之后运行任务,或者定期执行任务。
ScheduledThreadPoolExecutor的功能与Timer类似,但ScheduledThreadPoolExecutor功能更强大、更灵活。Timer对应的是单个后台线程,而ScheduledThreadPoolExecutor可以在构造函数中指定多个对应的后台线程数
ScheduledExecutorService scheduledExecService = Executors.newScheduledThreadPool(1);
可以使用 scheduleAtFixedRate 或 scheduleWithFixedDelay 在 ScheduledExecutor 中定期的执行任务。
scheduledExecService.scheduleAtFixedRate(Runnable command, long initialDelay, long period, TimeUnit unit)
scheduledExecService.scheduleWithFixedDelay(Runnable command, long initialDelay, long period, TimeUnit unit)
WorkStealingPool
Java 8 才加入这个线程池,其内部会构建ForkJoinPool,利用Work-Stealing算法,并行地处理任务,不保证处理顺序。
适用场景
SingleThreadScheduledExecutor适用于需要单个后台线程执行周期任务,同时需要保证顺序地执行各个任务的应用场景。
参考
10分钟搞定 Java 并发队列好吗
Java-BlockingQueue 接口5大实现类的使用场景
Java线程Executor框架详解与使用
谈谈你对JDK中Executor的理解?
Executor框架详解(Executor框架结构与框架成员)