客户端消费者
java示例代码
public class KafkaConsumerAnalysis {
public static final String brokerList = "HOSTNAME:9092";
public static final String topic = "quickstart-events";
public static final String groupId = "group.demo2";
public static final AtomicBoolean isRunning = new AtomicBoolean(true);
public static Properties initConfig() {
Properties props = new Properties();
props.put("key.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
props.put("bootstrap.servers", brokerList);
props.put("group.id", groupId);
props.put("client.id", "consumer.client.id.demo");
return props;
}
public static void main(String[] args) {
Properties props = initConfig();
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList(topic));
try {
while (isRunning.get()) {
ConsumerRecords<String, String> records =
consumer.poll(Duration.ofMillis(10000));
for (ConsumerRecord<String, String> record : records) {
System.out.println("topic = " + record.topic()
+ ", partition = " + record.partition()
+ ", offset = " + record.offset());
System.out.println("key = " + record.key()
+ ", value = " + record.value());
//do something to process record.
}
}
} catch (Exception e) {
log.error("occur exception ", e);
} finally {
consumer.close();
}
}
}
kafka消费者采用的是拉的模式,需要消费者主动调用poll来获取消息。
kafka订阅的方式有三种,他们之间是互斥的,即只能通过通过一种方式进行订阅
- 订阅主题,如示例代码,通过订阅特定topic上的消息
- 使用正则表达式订阅topic,订阅符合正则表达式的topic
- 订阅指定topic上的分区
poll方法可以接受一个Duration参数,表示阻塞时间。注意,不要理解为经过特定时间就唤醒一次,这里是阻塞超过特定时间或者有新消息时就会唤醒。
对数据进行消费时,除了示例代码中的对每一条消息进行处理,还可以通过ConsumerRecords的partitions()方法来讲消息根据分区分类,通过分区的维度来进行消息处理。
位移提交
kafka中的消息并不是消费完之后就删除掉。他会进行存储,所以对于一个新的消费者而言,他是可以消费到以前的所有消息的。
但是为了保证我们不重复消费,以及记录我们消费者消费到哪个地方,kafka会持久化保存消费位移。
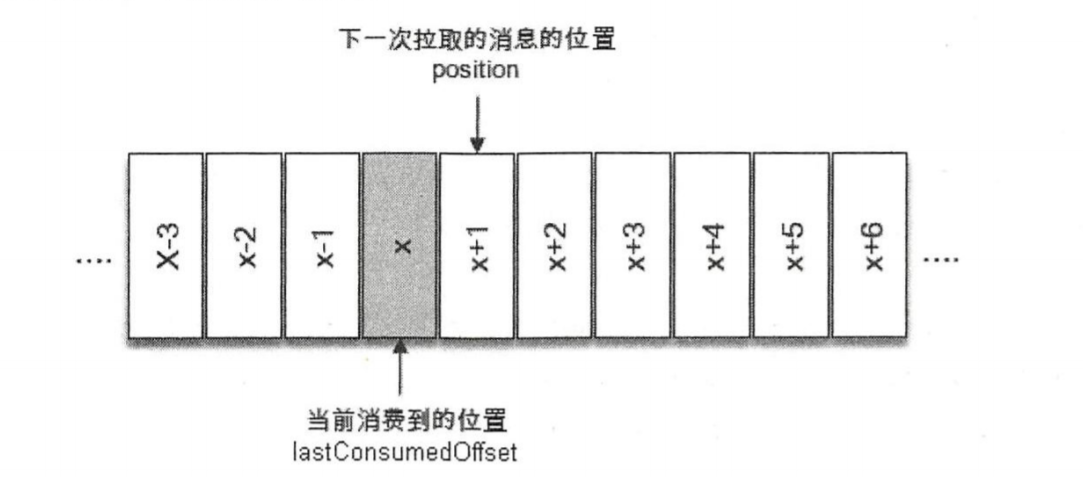
消费位移:表示消费者已经消费完提交的位置,具体值为消费者已消费完成的下一个位置,表示下次需要拉取的位置。
有了消费位移,我们在消费者断开重启,获取加入新的消费者的时候,才能知道之前topic中的分区消息被消费到哪个位置,从而避免重头开始进行消费。
如上图中,lastConsumedOffset表示最近消费完成的位置,而我们的消费者进行提交时的位置为lastConsumedOffset+1;
而至于什么时候进行提交,提交早了和提交晚了可能会导致重复提交和消息丢失的现象。
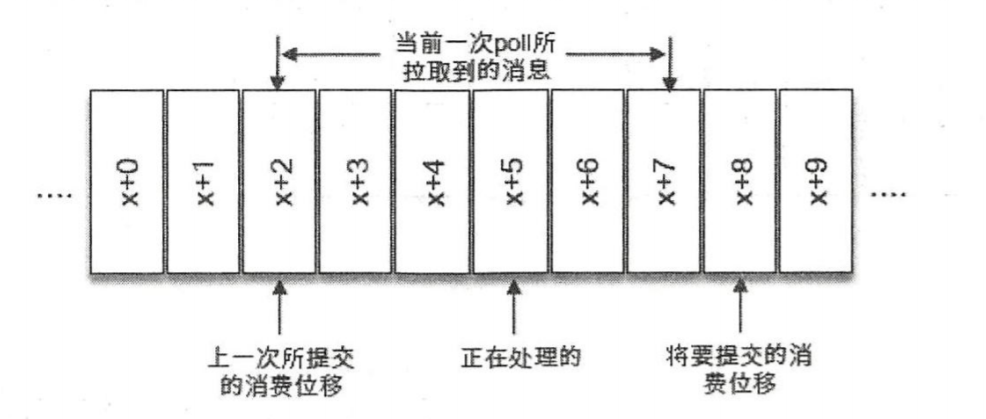 比如前面的代码,每次poll之后,我们立马进行提交,如上图,我们提交了x+8,然后再进行消息的消费逻辑处理。如果在处理的过程中失败了,我们重启消费者后,此时拉取到数据是从x+8开始的,我们就丢失了中间的部分消息。
比如前面的代码,每次poll之后,我们立马进行提交,如上图,我们提交了x+8,然后再进行消息的消费逻辑处理。如果在处理的过程中失败了,我们重启消费者后,此时拉取到数据是从x+8开始的,我们就丢失了中间的部分消息。
在比如,我们是在消息全部消费完成之后在进行提交,如果在消费的过程中失败了,此时我们消息处理了x+2~x+5。消费者重启之后,由于前面没有提交,此时我们最后提交的位置还是x+2,此时在重复拉取x+2 ~ x+7的数据,我们就重复消费了x+2 ~ x+5之间的数据。
默认情况下,消费者每隔5秒回将拉取到的每个分区中最大的消费位移进行提交。自动位移提交动作是在poll()方法的逻辑完成的。在每次真正向服务端发起拉取请求之前,会检查是否可以进行位移提交,如果可以,会先提交上次轮询的位移,在进行拉取。
自动位移提交也可能发生重复消费和消费丢失。延时消费容易产生的问题就是重复消费。而消费丢失的场景,出现在有另外一些线程异步去处理消息时,比如一个线程负责接受消息,将消息放入内存队列中,由另外一个线程负责消费,如果消息接收的速度快过消费线程消费,那么就可能造成消息丢失。
这种自动延时提交,方便简洁,一般情况下也不会发生消息丢失和重复消费的想象。不过无法做到精确的位移管理。kafka为了满足特定的位移提交需求,提供了手动提交位移的api,分为同步提交和异步提交。
- 同步提交:提交位移时会阻塞直到位移提交成功返回
- 异步提交:提交位移时立即返回
消费者可以指定在没有找到消费位移时该如何消费,默认是从分区末尾开始消费消息。也可以设置到为从头开始消费。
当然,我们也可以在指定哪个分区从哪里开始消费。
再均衡
再均衡值得是分区的所属权从一个消费者转移到另一个消费者的行为,比如消费者组删除消费者或者新增消费者,再均衡期间,消费者组怒的消费者是无法读取消息的。也就是这期间消费者组不可用。
这个不可用可能导致的结果,就是可能有的消费者消费完一个分区的消息后,还没来得及提交消费位移,就进入了再均衡,而分区被分配给新的消费者后,他并不知道上次消费完的位置,导致重复拉取消费。
我们客户端消费者在消费的时候,通过订阅topic或者正则订阅topic,可以事项再均衡监听器ConsumerRebalanceListener,该接口有以下两个方法
- void onPartitionsRevoked(Collection
partitions):再均衡开始之前,消费者停止读取消息之后调用,可以在这里提交消费位移,参数为目前的分区; - void onPartitionsAssigned(Collection
partitions):重新分配分区之后,开始读取消息之前。参数为分配后的分区。
线程安全
生产者KafkaProducer是线程安全的,然而KafkaConsumer却是非线程安全的。KafkaConsumer的每个操作,都会先执行acquire()来判断当前操作是否是同一个线程,多线程同时操作会直接抛出异常
private void acquire() {
long threadId = Thread.currentThread().getId();
if (threadId != currentThread.get() && !currentThread.compareAndSet(NO_CURRENT_THREAD, threadId))
throw new ConcurrentModificationException("KafkaConsumer is not safe for multi-threaded access");
refcount.incrementAndGet();
}
这里就是根据当前的线程进行判断,如果当前已有占用的线程,如果线程id相同,则引用计数加1,否则尝试cas设置,如果设置成功,说明当前没有线程占用,否则抛出异常。