[TOC]
zk的分布式模式同样是主从的模式,会有一个主节点(leader)处理所有的写操作,然后利用消息广播同步到所有从节点,客户端可以在所有的节点上提交写请求,只是提交到从节点的写请求会被转发主节点执行。
崩溃恢复是在主节点不可用之后,先进行leader选举,然后同步数据的过程。在这个过程中将不会执行新的写请求,知道崩溃恢复之后重新进入消息广播阶段。
消息广播
ZAB 协议的消息广播过程使用的是一个原子广播协议,类似一个 二阶段提交过程。对于客户端发送的写请求,全部由 Leader 接收,Leader 将请求封装成一个事务 Proposal,将其发送给所有 Follwer ,然后,根据所有 Follwer 的反馈,如果超过半数成功响应,则执行 commit 操作(先提交自己,再发送 commit 给所有 Follwer)。
具体过程
-
leader节点收到一个事务请求,会为该事务生成一个Proposal,并且为该Proposal分配一个全局唯一的递增ID,称为事务ID(ZXID),用于保证事务被顺序处理。
-
leader会为每个follower分配一个单独的队列,Proposal会被依次加入到这些队列中,根据FIFO的策略进行消息发送。
-
follower服务器接收到这个Proposal后,会将其以事务日志的形式写入到磁盘中,并在写入成功之后给leader发送一个Ack响应。
-
leader在接受到超过半数的Ack响应后,会广播一个Commit消息给所有的follower让他们提交事务,同时提交自己。
整个消息广播模式都是基于具有FIFO特性的TCP协议来进行网络通信的。
崩溃恢复
在leader节点不可用后,可能是是程序崩溃,或者网络原因导致leader服务器失去了与过半follower的联系,就会进入崩溃恢复的模式。
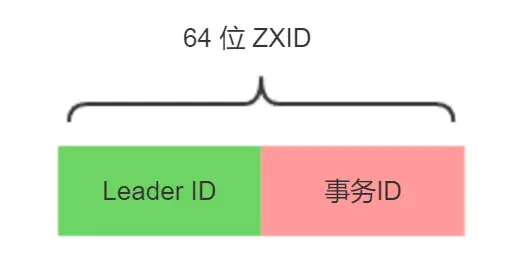
首先进行的就是leader选举,在选举之前,要先了解一下ZXID。ZXID是一个64位整数,它分为前32位和后32位。后32为就是用来标识事务唯一的,每一个新事务后32位就会递增1。 前32位称为epoch,可以理解为年代,每一个新leader的诞生都会将该值+1,然后重置后32位为0;
leader选举
注意,最终选举出来的是拥有最新提交的ZXID,而不是最新的ZXID;
- 选epoch最大的
- epoch相等,选 zxid 最大的
- epoch和zxid都相等,选择server id最大的(就是我们配置zoo.cfg中的myid)
节点初始时都会投票给自己,然后发送自己的选票给其他节点,当接收到其他节点的选票时,根据上述的条件进行比较,然后更新自己的选票,重新发送选票给其他节点,当有一个节点的选票超过半数时,给节点就会将自己的状态设置为leading,其他节点则会设置为following。
- ZAB确保那些已经在 Leader 提交的事务最终会被所有服务器提交(已经发出commit了)。
- ZAB确保丢弃那些只在 Leader 提出,但没有提交的事务。
数据同步
通过选举我们知道,选举出来的leader一定拥有最新的提交(根据最大ZXID选举出来),leader服务器会将那些没有被follow服务器同步的事务以Proposal的形式发送到各个follow对应的队列上,然后紧接着在跟一个Commit消息,表示该事务以及被提交。等到follow同步成功之后,就会将同步成功的follow加入到可以follower列表中。
事务的丢弃操作
比如当一个曾经的leader节点恢复后以follower身份加入到集群中后,leader会根据自己服务器上最后被提交的Proposal和该follower的Proposal进行比较,比对的结果就是leader会要求follower进行回退,回退到一个确实已经被超过半数的机器提交的最新事务上。
而其他原本的follower,会根据自己 最新的ZXID与leader的 最新提交ZXID进行比较,如果follower的ZXID大于leader的ZXID,则会要求follower回退未提交的Proposal。
这里有一个疑问,就是如果leader接收到超过半数ack后,本地提交了,但是却没有发出过commit,也就是leader是提交了,但是其他follower都还没提交,那么该如何处理? 目前的猜测就是,leader选举是根据已经提交的最大的ZXID,那么当前leader肯定是没有原leader的最新提交的,所以原来的事务也被当场只在leader提出,没有提交的事务,最终会被删除。所以leader提交的事务定义是除了leader之外,也有follower提交了的事务。