[TOC]
简介
ZooKeeper is a high-performance coordination service for distributed applications. It exposes common services - such as naming, configuration management, synchronization, and group services - in a simple interface so you don’t have to write them from scratch. You can use it off-the-shelf to implement consensus, group management, leader election, and presence protocols. And you can build on it for your own, specific needs.
核心概念和特性
zookeeper,为分布式程序提供分布式协调服务。
命名空间
每个分布式程序服务在zookeeper都是命名空间中的一个节点,该节点称为znode; 节点之间的关系类似文件系统的架构,有目录和文件,但是这里目录也是一个节点,其实就是一颗以/进行拆分的树。
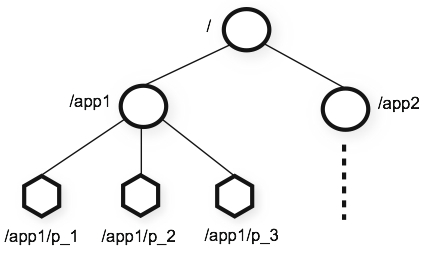
znode存储数据协议数据,如 状态信息,配置信息,位置信息等,这些数据通常都很小,只有字节到千字节之间的大小。
znode维护一个状态结构包括数据版本号,访问控制更改 还有时间戳 ,以允许缓存验证和协调更新。znode的数据每改变一次,版本号就自增1。在检索znode的数据时也会返回该版本号。
znode的读写是原子性的。堵获取znode的所有数据,写着替换该znode的所有数据,并且有一个ACL来限制谁可以做什么。
znode的数据是存储在内存中的,可以保证高吞吐和低延迟。
watch
zookeeper支持监听znode,当一个client在一个znode上设置watch后,znode一发送改变,watch将会触发并且被删除。一旦被除非,client将会收到一个数据包,说明znode已经被改变。如果客户端和其中一个zookeeper服务器连接中断,客户端将收到一个本地通知。
zookeeper服务 主从结构(ZooKeeper is replicated.)
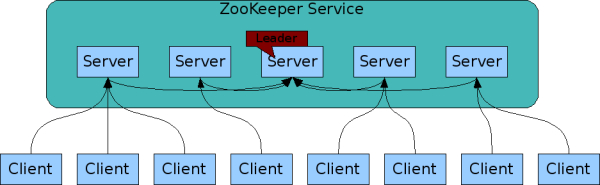 整个服务有多个副本节点,每个client可以连接到任意一个client上进行操作,保证zookeeper高可用。client与某个server维护一个TCP连接,通过该连接发送请求,获取响应,获取监听事件和心跳检测。如果tcp连接断开,则可以重新选择一个server进行连接。
整个服务有多个副本节点,每个client可以连接到任意一个client上进行操作,保证zookeeper高可用。client与某个server维护一个TCP连接,通过该连接发送请求,获取响应,获取监听事件和心跳检测。如果tcp连接断开,则可以重新选择一个server进行连接。
每个service都一份内存数据库副本,他存储了整颗树的数据。更新被记录到磁盘上,以便恢复,写操作在应用到内存数据库之前被序列化到磁盘,作为内存数据的快照。client的读取请求可以直接在副节点上执行,更改状态的请求(写请求)则会被重新转发到leader服务上,
zookeeper的特性(保证)
- 顺序一致性: 来自client的更新操作将按照他们发送的先后顺序执行
- 原子性: 要么更新成功要么失败,不会有中间状态
- 单一系统镜像:zookeeper是主从结构,它保证不管client连接的是哪个server,他们与其他server都是一致的,即整个系统都是一致的。
- 可靠性:一旦更新被执行,该状态将被保存知道新的更新进行覆盖
- 及时性:保证client看到的系统在一定得时间范围内都是最新的。
zookeeper简单的api
- create:创建一个节点
- delete:删除一个节点
- exists:判断节点是否存在
- get data:获取节点数据
- set data:更新节点数据
- get children:获取节点的子节点
- sync : 等待数据传播