Hashtable、HashMap、TreeMap基本特征对比
- Hashtable:同步的,不支持null键和值;
- HashMap:不同步的,支持null键值,底层用数组+链表(可进化为树)进行存储;
- TreeMap:基于红黑树的顺序访问map,它的get put remove操作都是O(log(n));具体顺序可以实现Comparator来决定;
LinkedHashMap与TreeMap
- LinkedHashMap:通过遍历时按插入顺序返回;底层使用双向链表存储键值对,但是,如果对其进行访问,会动态调整键值对的位置,最近访问(get,put,compute等)的会被调到队头,并且在需要删除的时候,会先删除出掉队头的ky;
- TreeMap:整体顺序与键有关,由Comparator或Comparable来决定;
hashmap源码总结
1.7之前 死循环的原因
头插法的缘故,因为扩容之后,原本链表的顺序会颠倒,假设原来为 6->8->null;之后为 8->6>null;
这里假设第一个线程在获得e = 6,next = 8的情况下被挂起;那么另外一个线程扩容完毕后,8->6->null;
此时执行A, 按照原本的逻辑,8->null;但是现在8->6->null;导致A在获取8.next的时候得到了6,多执行了一遍循环,形成了6->8->6的循环链表;
那么以后在遍历该链表的时候就会陷入死循环;
结构图
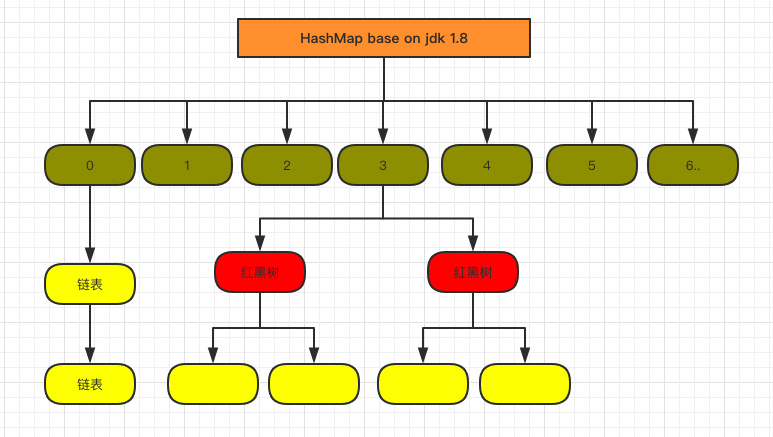
putVal
- hashMap在构建成功之后,不会马上申请空间,而是在第一次put的时候,在进行申请;容量大小根据设置的值或者默认16进行申请;
- 初始默认大小为16,并且每次扩容为原来大小的2倍;最大为==2^30==;
- 有一个阈值的概念,阈值计算方式为 ==容量*负载因子(默认0.75)==;每次扩容阈值也同样为原来的两倍;
- 当某个桶中的链表长度==大于8==(TREEIFY_THRESHOLD)时,如果数组容量==小于64==,则只会进行扩容,如果==大于64==,则会进行树化;
hashCode的原理
根据哈希值计算下标取出目标值是这样的;
first = tab[(n - 1) & hash]
n是数组长度,这里就是长度-1;hash是key的哈希值;这里从侧面体现出了为什么HashMap的数组长度要取2的整次幂,因为这样长度-1就刚好是“低位掩码”;与操作的结果就是hash的对应低位与掩码,用来做数组下标进行访问;假设n=16,2进制就是00001111;进行如下计算
10100101 11000100 00100101
$ 00000000 00000000 00001111
----------------------------------
00000000 00000000 000000101 //高位全部归零,只保留末尾;
从以上描述其实可以看出问题,如果hash值只是单纯的通过key.hashCode()来获取的话,那么就算散列值在松散,其决定作用的都是在最后几位,取决与n有多大,但是我们一般的数组容量都不会太大,可能就在2^16(65535)以内,但是hash的值却可以是-2147483648到2147483648;导致很多高位的hash值没有参与;更极端的情况下,如果本哈希没做好,导致低位基本是一样的,那碰撞就会很严重;
这个时候我们再来看看hashMap中是如何计算hash的值:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
这里简单的说,就是那hashCode的高16位与自身低16位进行异或,结果作为hash值;
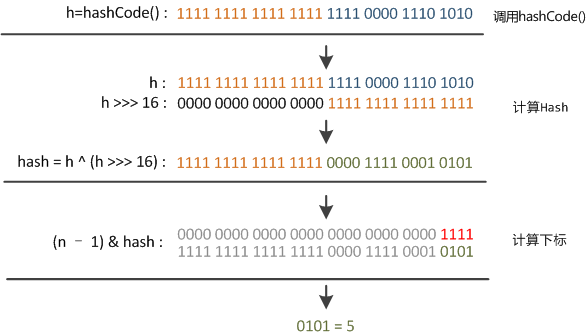
这里以32位位例,自己的高半区与低半区异或,能起到混合原始哈希码的高位和低位的作用,将高位的信息也变形的保留下来,参与到哈希取模,获取数组下标的计算中,而不在只是低位起作用而已了;