要解决的问题-分布式调用链
- 自动采集数据
- 能够分析数据,产生==完整的调用链关系==
OpenTracing
OpenTracing 规范一套规范,定义了分布式追踪系统的API,类似JDBC那样;
- Trace:表示一个完整的请求链路
- Span:一次调用过程(有开始时间和结束时间)
- SpanContext:Trace的全局上下文信息,包含有TraceId
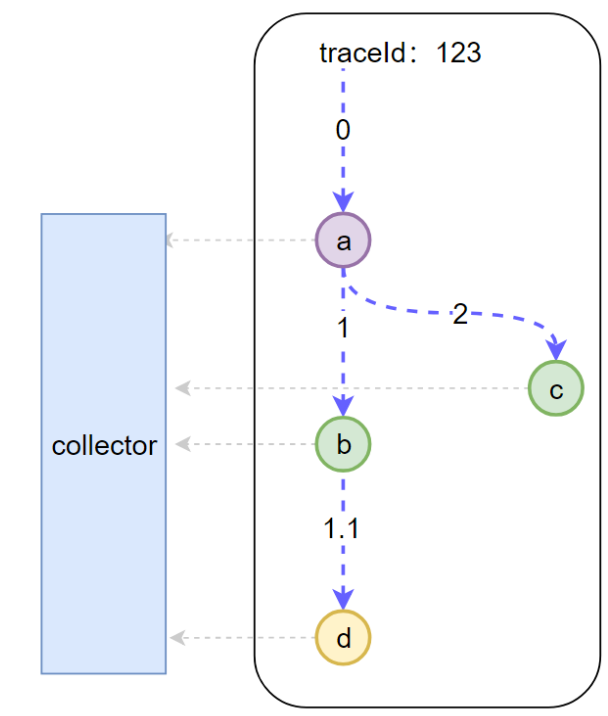
一次完整的调用链关系如上图,每一层调用,如abcd都会产生一个span,有span_id和parent_span_id来表示调用的关系;彼此之间可以通过SpanContext来传递TraceId;
收集到的span信息,在各自的服务会将数据传递给conllector,之后就可以根据这些信息得到完整的调用链关系图了
SkyWalking主要实现原理
为了实现上面的需求,我们有以下问题需要解决
- 如何传递context,也就是traceId等信息
- 如果自动采集cpan数据,发送给collector
skyworking对代码是无侵入的,主要是利用javaagent+插件化的方式,在代码启动之前,对需要监控的接口进行动态代理,在真正调用接口逻辑之前就准备好了计时,结束之后将span数据发送给collector;有了这一步实现,那么自然就可以很方便的做一些操作
而跨进程甚至是跨服务之间进行context数据的传递,特别是TraceId的传递,毕竟我们需要根据TraceId来确定他们是属于同一个Trace的; 以dubbo为例子,skyworking拦截dubbo请求,在调用者这边调用之前加入skywalking跨进程协议header信息,然后生产者同样在拦截器处将数据取出来;
skywalking总体架构
- skywalking-collector:链路数据归集器
- skywalking-web:web可视化平台,用来展示落地的数据
- skywalking-agent:探针;用来收集和发送数据到归集器;
参考
https://my.oschina.net/u/4418565/blog/4653959