一次问题记录,前前后后跨了一个半月,因为当初刚发现这个问题没多久,就换了新的服务器,所以目前无法重现当时遇到问题的情况,好在当时记录的也比较详细,截图都有,所以还凑合着可以分析。因为很多原理的东西没搞明白,所以也就拖着拖着慢慢分析,最终的结论只是我的猜测,并不是最终结果,而且水平有限,大部分都只是根据别人的结论进行推导和总结而已。
记录现象
在9点10几分开始运行,查看输出的结果,到第二天早上6点半就无法发送了。而且kibana也上不去了。使用top查看内存使用情况
master节点

Node节点

而且询问了一下,也说是cpu和内存都满了。
在仔细查看一下top命令
Master节点

Node节点

cpu使用率也基本占满了,其中占master节点主要花费在等待IO上和内核空间使用。
但是在排查的过程中,再次查看node节点的情况,发现cpu和内存都已经正常,而master节点却还是不行,内存和cpu使用都很高,而且cpu占用最高的还是wa,IO等待现象比较严重,可能是磁盘大量频繁读写造成的。 查看cpu使用率最高的进程发现时swap0,查了一下这个是跟虚拟内存有关的,当内存不足时会对换磁盘出来使用,但是我是使用k8s部署的,k8s必须关闭swap才可以建立集群,所以不应该会导致这种情况才对啊。。。而且也没有说占到很多。


很显然的不足,查看时哪个进程用了那么多

好吧,元凶在这,elasticsearch占用了太多内存。
在尝试重启了es之后,刚开启没多久是可以正常运行,但是好景不长,过不了多久他又重新陷入崩溃状态,kibana打不开,而且我发现只要master节点在哪,哪台主机的cpu和负载就会特别高。cpu的大部分消耗都花在等待io上。
查看整个的负载情况和io使用情况
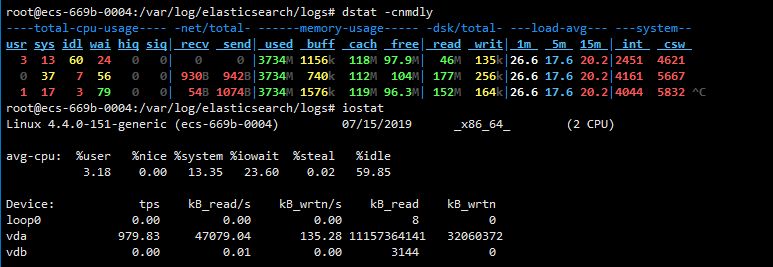
#### 观察io
root@ecs-669b-0004:/var/lib/elasticsearch/data/nodes/0/indices/AnltW8msTFaQj7RQ2lvBTg/0/index# sar -B 1
Linux 4.4.0-151-generic (ecs-669b-0004) 07/15/2019 _x86_64_ (2 CPU)
09:20:25 AM pgpgin/s pgpgout/s fault/s majflt/s pgfree/s pgscank/s pgscand/s pgsteal/s %vmeff
09:20:26 AM 114730.10 194.17 2756.31 1117.48 28447.57 41438.83 0.00 28040.78 67.67
09:20:27 AM 100452.00 96.00 2397.00 910.00 26667.00 40498.00 0.00 26206.00 64.71
09:20:28 AM 124224.00 252.00 3003.00 1185.00 29208.00 43410.00 510.00 28986.00 66.00
09:20:29 AM 91548.51 114.85 2262.38 910.89 23349.50 32452.48 423.76 22899.01 69.65
09:20:30 AM 113450.51 177.78 3078.79 1156.57 30384.85 44295.96 0.00 29678.79 67.00
09:20:31 AM 68559.18 142.86 1802.04 633.67 14162.24 24458.16 897.96 13163.27 51.91
09:20:32 AM 153172.82 341.75 3529.13 1442.72 40691.26 61179.61 1339.81 40374.76 64.58
iostat -x -k -d 1
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
loop0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
vda 0.00 5.00 2601.00 11.00 105908.00 64.00 81.14 41.04 15.70 15.10 158.18 0.38 99.60
vdb 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
负载
系统负载是对当前CPU工作量的度量,被定义为特定时间间隔内运行队列中的平均进程数。load average 表示机器一段时间内的平均load。这个值越低越好。负载过高会导致机器无法处理其他请求及操作,甚至导致死机。
Linux的负载高,主要是由于CPU使用、内存使用、IO消耗三部分构成。任意一项使用过多,都将导致服务器负载的急剧攀升。
如果你看到load average数值是10,则表明平均有10个进程在运行或等待被运行。
swap
swap值的时交换分区或文件,主要有用于在物理内存不足或者很少使用的内存页占用太多时间时,用来将内存页中的数据暂时换到磁盘中,以将内存让给其他急需要使用的进程。在内存不足,进程异常导致大量交换分区时会导致严重的性能问题。
kswapd
内核的页回收机制有两种:后台回收和直接回收。 后台回收是有一个内核线程 kswapd 来做的,当内存里 free 的 pages 低于一个水位(page_low)时,就会唤醒该内核线程,然后它从 LRU 链表里回收 page cache 到内存的 free_list 里头,它会一直回收直至 free 的 pages 达到另外一个水位 page_high.
线程在申请内存的时候,发现该 zone 的 freelist 上已经没有足够的内存可用,所以不得不去从该 zone 的 LRU 链表里回收 inactive 的 page,这种情况就是 direct reclaim(直接回收)。direct reclaim 会比较消耗时间的原因是,它在回收的时候不会区分 dirty page 和 clean page, 如果回收的是 dirty page,就会触发磁盘 IO 的操作,它会首先把 dirty page 里面的内容给刷写到磁盘,再去把该 page 给放到 freelist 里。
mmap
Elasticsearch默认使用mmapfs目录存储索引。mmapfs类型通过将文件映射到内存来存储文件系统上的碎片索引文件。是一种内存映射文件的方法。即将文件映射到进程的虚拟内存地址空间中,实现文件磁盘地址和进程虚拟地址空间中一段虚拟地址的一一对应关系。
进程读写映射地址时,查询页表,发现数据不在物理页面上,因此引发缺页异常。调用过程现在交换空间中寻找需要访问的内存页,如果没有则调用nopage函数将所缺的页从磁盘装入到主存中。之后读写操作会在一定时间后自动写回到对应磁盘地址。
mmap操控文件比起常规的文件操作少了一次数据拷贝。常规的需要从磁盘拷贝到页缓存在拷贝到用户主存,而mmap只需要从磁盘到用户主存的一次数据拷贝过程。
max_map_count定义了进程能够拥有的最多内存区域,默认是65535,这对es来说是不够用的,所以推荐设置为262144,否则容易引发内存不足的问题。
niofs
niofs使用NIO在文件系统上存储碎片索引,它允许多个线程同时从一个文件中读取数据。
索引文件在heap中
还要澄清一下,我文章里说的常驻heap的,是用于快速访问segment文件的一种索引结构。 segment本身不会常驻heap,只有被搜索访问到的文件块会被os page cache缓存。
原因可能是什么?
从最直观的数据来看,系统负载高,cpu使用率接近百分之百,且大部分用于磁盘io,以read为主。内存不足,并且开启了kswapd进程回收。交换分区已经关闭。最直接感受到的原因就是内存不足。实际上在换了新的服务器之后(由4g内存升级为32g内存)页确实再没出现过这种问题。
起初认为是由于内存不足导致开启了kswapd进程进行内存页的和磁盘的交换,从而使磁盘io骤升,进而导致系统负载飙升;但是有个疑惑时,当时的交换区已经关闭,并且可以查看到交换区的几乎没有在使用。而且大部分也都是read,那么到底时怎么导致的磁盘io如此频繁?
仔细查了一下才发现对kswapd这个进程的理解有误,这个进程是在空闲内存页低于一定数量时会由内核自动开启来进行内存页的回收,以保证空闲内存页维持在一定的数量。因为除了内核自动回收之外,当进程在申请内存的时候,若发现所申请的内存页小于可用空闲页,则会进行由进程发起的强制内存页回收。而这是一个耗时的操作,若此时每一个新来的进程都需要申请同样一片内存,那么就会不断的进行回收,大部分cpu时间都花费在内存的回收上了,导致性能下载和负载的升高。所以一种可能的解决方法是提高内存自动回收的水位,使其在空闲的时候多回收一些内存,这样在后续需要遇到需要申请大片内存的进程时才会触发强制回收。
所以针对我们的问题,高负载,又有kswapd进程在不断回收,所以内存不足导致进程强制回收内存,造成许多进程等待内存的回收,从而导致高负载的情况。
但是磁盘io如此频繁却又不是内存回收引起的。此时继续研究,发现es中对索引文件的存储方式是mmapfs,是一种内存映射文件的方法,可以实现直接将文件的数据读取进内存中。而且对es中索引文件的使用进行一些研究之后,发现es中是使用很多的segment文件来存储索引数据的,每个segment文件都是独立的索引文件,当查询某个index索引下的数据时,是需要查询若干个segment文件并将结果汇总起来的。所以每次查询都需要读取许多的文件。所以再内存不充足的情况下,就会可能导致这些索引文件被频繁的踢出内存,再被反复的读入,而读入的操作就是导致了磁盘io的read如此之高的原因。
又在翻了很多文档资料之后,发现github上有人提了类似的issue,虽然他们大部分的讨论我都没怎么看懂。。。但是从他们讨论的结果中,有提及说使用niofs代替mmapfs存储索引文件后,就不会出现上述的问题。说是mmapfs会对数据进行预读,简单的说就是或加载额外没用的数据,占用更多的内存空间 Mmap fs可能让大索引访问变得缓慢
参考
ES中使用mmap存储的索引会锁定内存不释放?
ES集群服务器CPU负载瞬间飚高分析
File system storage typesedit
Day19 ES内存那点事