倒排索引
elasticsearch底层是使用Lucene的倒排索引技术来实现比关系型数据库更快的过滤,在了解什么是倒排索引之前,先明白几个关键词的意思。
- index:索引,在倒排索引里一个index就相当于一个数据库。
- document:文档,一个文档归属一个索引下面,有自己的docId。相当于一条数据。
- field:字段,一个文档由多个字段组成。
- term:字段的内容,就是某个field的值,大部分情况下都有多个值。
- posting list: docId的集合。
例子 docid | 年龄 | 性别 | —|—|—| 1 | 18| 女| 2 | 20 | 女| 3 | 18 | 男|
假设我有一个索引为person,而上述表格中每一行就是代表一个文档,field就是年龄,性别。而年龄的term就是18 20,性别就是男女。则上述关系存在如下的倒排索引
年龄
| term | posting list |
|---|---|
| 18 | [1,3] |
| 20 | [2] |
性别
| term | posting list |
|---|---|
| 女 | [1,2] |
| 男 | [3] |
所以不同于我们平时在关系型数据库里使用的索引,比如为id建立一个索引,然后通过b+tree去加快搜索。当我们需要根据年龄的具体数值去查询某一部分数据时,正向索引是根据索引二分查询得到结果(如果没有索引则是遍历所有得到结果);而倒排索引则是根据term到postring list的映射,直接获得关键字对应的文档列表。
当今的搜索引擎检索算法也是基于倒排索引来实现的。所以倒排索在多条件的过滤和组合查询上性能要高过正向索引。
根据倒排索引检索
假设我们某个field上有很多值,比如姓名。如果每个姓名都不重复,且是乱序的,那么根据名字这个关键字去检索也还是需要全部遍历一遍。所以term还是需要排序的,排好序之后便可以使用二分查找加快排序速度。而排序后的term就是term dictionary。
但是这样的话,不就跟普通数据库的索引查询一样了吗?数据库索引是通过将数据组织成b-tree的形式存放在物理盘上以减少磁盘的读写次数来提高检索性能,而es则是希望直接通过内存来查找term,不读磁盘。但是正如前面的名字feld,如果有很多条数据,每条都不重复,那么内存肯定不够放。于是es组织一棵树,这颗树不包含所有的term,它包含term的一些前缀到block之间的映射关系,在结合FST的压缩技术,使它能够存放到内存中,称为term index。
顾名思义,就是为了快速查找到term的索引。在内存中快速定位term的前缀所在block后,在去磁盘顺序查找term,大大减少了磁盘的读取次数。
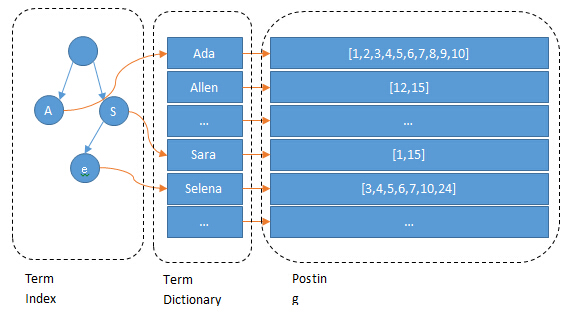
倒排索引-合并查询
当我们组合条件查询时,如搜索年龄为20,性别为男的数据时,es是先分别查询得到他们的posting list。然后在对这两个postlist进行合并。合并的方法有两种,一种是Skip List合并;一种是bitset数据结构合并;如果查询的filter缓存到了内存中(以bitset的形式),那么合并就是两个bitset的AND。如果查询的filter没有缓存,那么就用skip list的方式去遍历两个on disk的posting list。
Skip List合并
假设我们查询的出来的两个posting list为
[10,100,200,300...800] [2,4,6,8,10.....,798,800];
假设我们直接对这两个数组进行遍历查找相同的元素,那么就需要比较很多次,而我们也可以看到,很多比较其实是没必要的。如果对于数组有对应的跳跃指针。如下面所示的第二个数组跳表
[2-->50-->100...-->800]
[2,4,6,8,10.....,798,800]
那么当比较来到10时,双方相等,前者下一个元素为100,后者下一位元素为12,很明显12小于100,那么查看12的下一跳50也小于100,所以直接到到50,然后50也小于100,50的下一跳为100,则直接跳到100。这样就可以跳过中间的很多比较,得到最终的合并结果。
压缩
考虑到频繁出现的term(所谓low cardinality的值),比如gender里的男或者女。如果有1百万个文档,那么性别为男的 posting list 里就会有50万个int值。Lucene 采用Frame Of Reference(FOR)来进行压缩
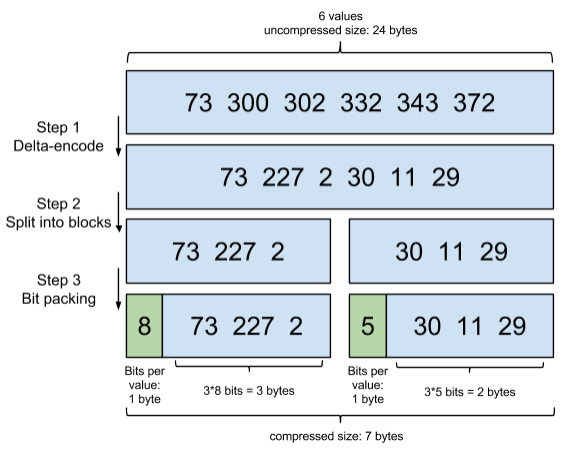 由于列表已经是排好序的,所以前后差值不会小于0;
由于列表已经是排好序的,所以前后差值不会小于0;
- 首先将将原列表转化为与前一个数的差值
- 然后将这些差值放到不同的块中
- 进行位压缩,取最大值为当前块存储的位数,比如30、11、29中最大数30最小需要5个bit位存储,这样11、29也用5个bit位存储
用Frame of Reference编码进行压缩可以极大减少磁盘占用
bitset合并
如有posting list
[1,3,4,7,10] 对应的bitset就为 [1,0,1,1,0,0,1,0,0,1];将bitset进行合并就只要进行与操作即可。
压缩
Bitset自身就有压缩的特点,其用一个byte就可以代表8个文档。所以100万个文档只需要12.5万个byte。但是考虑到文档可能有数十亿之多,在内存里保存bitset仍然是很奢侈的事情。而且对于个每一个filter都要消耗一个bitset,比如age=18缓存起来的话是一个bitset,18<=age<25是另外一个filter缓存起来也要一个bitset。
Lucene使用Roaring Bitmap(RBM)来进行压缩。其主要原理可以看下图
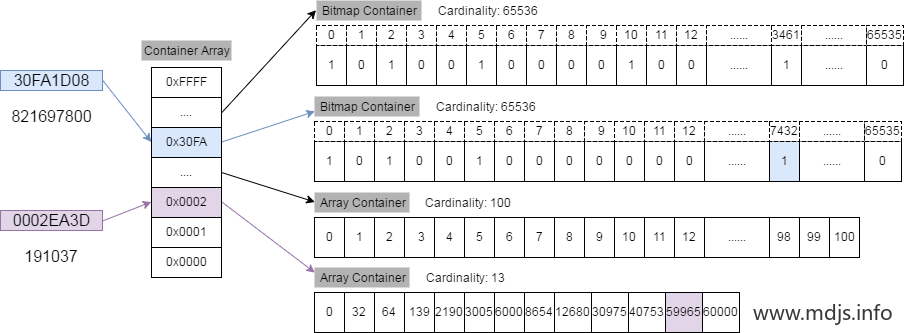 将一个32bit的数值分为高16位和低16位,按高16位寻找桶,按低16位存储在桶中。若一个 Container 里面的 Integer 数量小于 4096,就用 Short 类型的有序数组来存储值。若大于 4096,就用 Bitmap 来存储值。
将一个32bit的数值分为高16位和低16位,按高16位寻找桶,按低16位存储在桶中。若一个 Container 里面的 Integer 数量小于 4096,就用 Short 类型的有序数组来存储值。若大于 4096,就用 Bitmap 来存储值。
由于桶中具有两个存储方式,所以对于操作就有三种可能
- Array vs Array:直接merge两个Array;
- Array vs Bitmap:遍历Array,把Array中的值映射到Bitmap上操作
- Bitmap vs Bitmap:直接按位操作即可。
Segment文件
Segment文件中包含着一套完备的倒排索引,可以独立的进行查询。一个索引可以由多个Segment组成,所以在查询Index的时候需要对多个Segment进行查询并对结果进行合并。
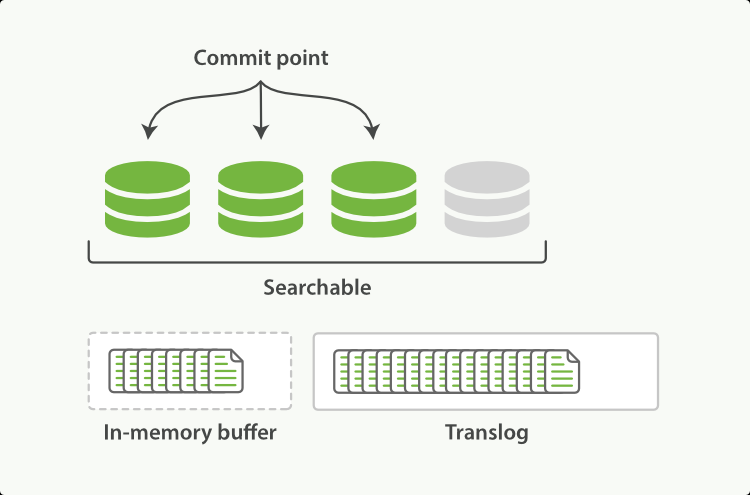
每当有新数据添加时,都会先添加到内存中,然后再经过一个refresh时间间隔(默认1s,可通过refresh_interval参数设置)后就会将数据写入文件系统缓冲区中,这样便可以对新进的数据进行查询。注意,此时仅仅只是写入到缓冲中,换句话说,一但重启数据将丢失。
为了保证数据不丢失,再将数据写入内存中时还会维护一份文件translog,translog也是一开始在内存记录,每隔五秒写一次磁盘,且在每次 index、bulk、delete、update 完成的时候,一定触发刷新 translog 到磁盘上,才给请求返回 200 OK。一旦重启服务器对于还没落盘的数据便可以通过translog来进行恢复。
如下图
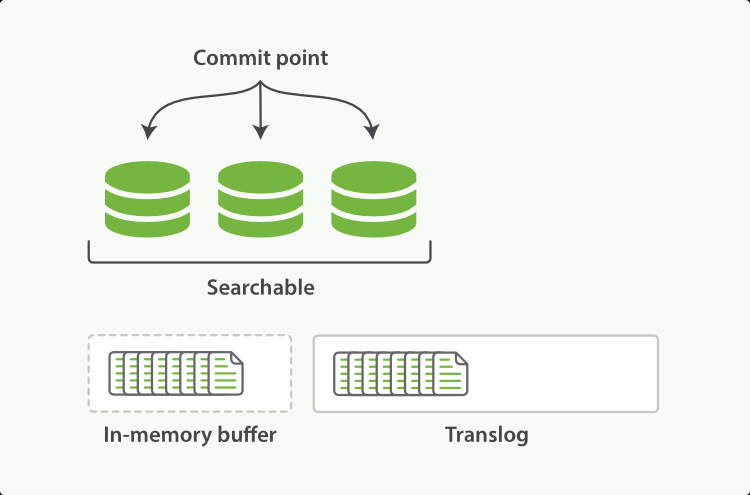 刷新到文件系统缓存中
刷新到文件系统缓存中
 在经过一个
在经过一个flush时间间隔(默认30分钟,index.translog.flush_threshold_period),或者当translog文件大小大于一定大小时(512MB,index.translog.flush_threshold_size),就会执行flush操作,将数据同步到磁盘。一旦写入磁盘,segment文件便不在修改,就算时update操作,也是先delete后重新创建。而后translog文件会保留一段时间,默认保留12小时。大小512m。
flush之后,重新添加的数据又会新生成一个Segment文件。所以这种机制会导致短时间内生成很多个segment文件,而文件是要占用文件描述符,而且每次搜索时都要从这么多个segment文件中去搜索,显然性能会非常底。所以es会在后台对segment做一个合并的操作,这个过程是有独立的线程来进行的。 合并完成后小的segment文件就会被删除。
归并线程是按照一定的运行策略来挑选 segment 进行归并的。主要有以下几条:
index.merge.policy.floor_segment 默认 2MB,小于这个大小的 segment,优先被归并。 index.merge.policy.max_merge_at_once 默认一次最多归并 10 个 segment index.merge.policy.max_merge_at_once_explicit 默认 forcemerge 时一次最多归并 30 个 segment。 index.merge.policy.max_merged_segment 默认 5 GB,大于这个大小的 segment,不用参与归并。forcemerge 除外。
常驻在heap的数据,是用于快速访问segment文件的一种索引结构,segment本身不会常驻heap,只有被搜索访问到的文件块会被os page cache缓存。
集群与分片
在es集群中,如下图
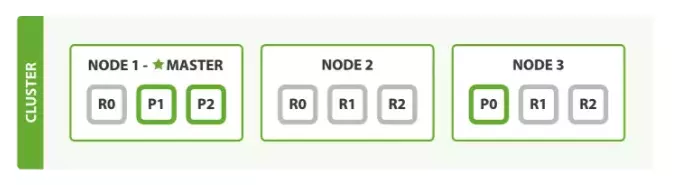 这个图表示的是该es集群中一共有三个节点,一个索引,三个主分片,一个分片对应两个副分片,一个6个副分片。索引的数据是分布在不同的分片上的。
而一个分片底层即是一个lucene索引。所以一个索引可以设置多个分片。每个分片包含多个segment;
这个图表示的是该es集群中一共有三个节点,一个索引,三个主分片,一个分片对应两个副分片,一个6个副分片。索引的数据是分布在不同的分片上的。
而一个分片底层即是一个lucene索引。所以一个索引可以设置多个分片。每个分片包含多个segment;
在分布式集群中,不同分片会位于不同的节点上,当向某一个节点发出请求时,会简单根据文档id哈希求模得到该文档所在的分片,进而路由到该分片所在的node,如果进行增删改的操作,在分片执行成功之后会并行发送请求到其他的副本分片上,只有等到报告成功之后才会向原来接受请求的节点报告成功,并由原来的节点返回给客户。
参考
索引的使用
https://www.cnblogs.com/linjiqin/p/10764101.html
索引原理
https://cloud.tencent.com/developer/article/1368187 https://www.cnblogs.com/dreamroute/p/8484457.html https://elasticsearch.cn/article/6178
segment
https://elasticsearch.cn/article/6178
https://www.jianshu.com/p/9b872a41d5bb
https://www.ctolib.com/docs/sfile/ELKstack-guide-cn/elasticsearch/principle/realtime.html
https://www.cnblogs.com/richaaaard/p/5226334.html
https://elasticsearch.cn/article/32
RBM
https://cloud.tencent.com/developer/article/1136054