elk介绍
elk不是一款软件的名字,是一套完整的集中式日志系统。elk代表的主要是三款软件,分别是elasticsearch,logstash,kibana。不过现在更多的还会多使用一个filebeat软件来进行日志数据收集。
这一整套协议栈能够提供轻量低内耗的收集器,强大的日志过滤与格式化,以及对日志文档数据的索引存储与快速搜索,并提供可视化界面来对日志数据和堆栈集群的健康状况进行分析,以便对分布式部署的服务架构,即服务散落在不同服务器上的服务进行快速分析与定位。
Elasticsearch
Elasticsearch 是一个分布式、RESTful 风格的搜索和数据分析引擎,能够解决不断涌现出的各种用例。 作为 Elastic Stack 的核心,它集中存储您的数据,帮助您发现意料之中以及意料之外的情况。
Logstash
Logstash 是开源的服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到您最喜欢的 “存储库” 中。(存储在Elasticsearch)
Kibana
通过 Kibana,您可以对自己的 Elasticsearch 进行可视化,还可以在 Elastic Stack 中进行导航,这样您便可以进行各种操作了,从跟踪查询负载,到理解请求如何流经您的整个应用,都能轻松完成。
Filebeat
Filebeat 将为您提供一种轻量型方法,用于转发和汇总日志与文件,让简单的事情不再繁杂。Filebeat 只是一个二进制文件没有任何依赖。它占用资源极少,尽管它还十分年轻,正式因为它简单,所以几乎没有什么可以出错的地方,所以它的可靠性也是很高的。
其实如果单纯说收集日志的功能的话,logstash是本身也是可以实现的,但是问题在于logstash使用java实现的,本身就十分消耗资源,所以就开发出了filebeat,使用go语言编写的轻量可靠,资源消耗极少的日志收集器。
架构
下图为我在实习的公司搭建的elk架构图,通过该图可以很明显的看到各个部件在整个协议栈中起的作用,在这里filebeat直接和我们的目标服务同放在一个pod中去收集服务产生的日志,并将数据输送给logstash进行过滤和格式化,然后输送给这个协议栈的核心elasticsearch进行数据索引和存储,最终我们将在kibana上对数据进行可视化和分析。
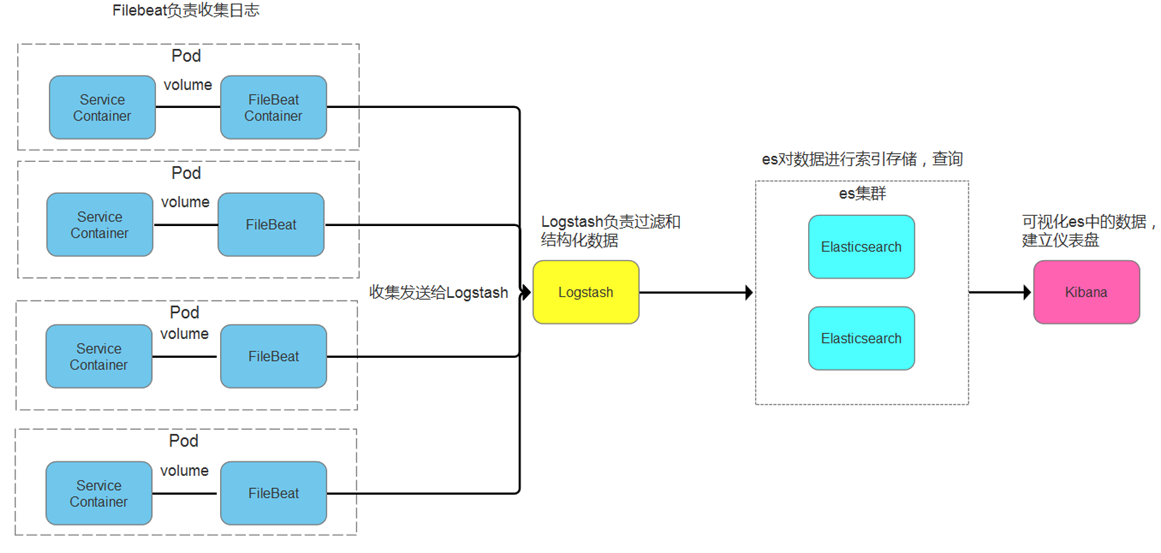
k8s上filebeat的两个部署方案
方案一是一台服务器上部署一个filebeat来收集日志(可使用(DeamonSet类型来部署) 将pod中的日志都挂载出来,然后启动单一个filebeat去收集。
这样的好处是只需要配置单一的filebeat文件,而且开启一个filebeat也比较节省资源,但是需要将所有的日志数据都挂载出来,所有的日志地址都需要在filebeat中进行配置,而且当所有服务产生的日志较多时,单个filebeat的压力也会比较大。也无法针对每个pod的日志产生配置相应的策略。
方案二就是这里采用的每个pod中都开启一个filebeat去收集。这样直接使用数据卷共享的方式去直接读取,而不需要将日志数据都挂载到宿主机上(一般为了数据的持久化,还是会挂载到宿主机上,不过如果能够忍受部分可能数据丢失的话,不挂载也没问题,毕竟最终的数据也会被存储在es上) 每个pod都有自己专用的filebeat,实现了低耦合,也允许针对不同的日志情况对filebeat进行配置;且相比较单个filebeat,分开后每个fileeat压力也不会单个那么大。
为什么需要消息队列来缓存
网上也查阅了很多架构的问题,大部分情况下除了以上的基本架构外,很多人都还会在中间加一个消息缓存队列。 主要是为了顶住突发尖峰等异常情况,如果瞬时间突然产生很多日志到logstahs或者到es中,那么就可能导致连接超时,数据丢失等问题,所以中间加个缓存层来避免这种情况。
部署详情
部署是在k8s上的,所以基本都是配置对应yaml的内容
部署环境
| hostname | 身份 | linux版本信息 | CPU个数 ,逻辑核数 | 内存大小 | 硬盘大小 |
|---|---|---|---|---|---|
| ip-172-31-11-34 | master | Linux version 4.4.0-150-generic Ubuntu 16.04.10 | 1,8 | 32945976 kB | 200G |
| ip-172-31-8-82 | node1 | Linux version 4.4.0-150-generic Ubuntu 16.04.10 | 1,8 | 32945976 kB | 200G |
elasticsearh集群部署示例
k8s本身就是一个用来部署集群的工具,所以在这上面部署es集群也是很方便的。不过有些细节需要注意。我们先来看yaml文件。
kind: List
apiVersion: v1
items:
- apiVersion: apps/v1beta1
kind: StatefulSet
metadata:
name: elasticsearch
spec:
serviceName: "elasticsearch"
replicas: 2
template:
metadata:
labels:
app: elasticsearch
spec:
containers:
- name: elasticsearch
image: ish2b/elasticsearch:7.2.0
resources:
requests:
memory: "17000Mi"
env:
- name: cluster.name
value: "es-cluster"
- name: node.name
value: "${HOSTNAME}"
- name: node.master
value: "true"
- name: node.data
value: "true"
- name: network.host
value: "0.0.0.0"
- name: ES_JAVA_OPTS
value: "-Xms16g -Xmx16g"
- name: discovery.seed_hosts
value: "elasticsearch-0.elasticsearch:9300,elasticsearch-1.elasticsearch:9300"
- name: cluster.initial_master_nodes
value: "elasticsearch-0"
ports:
- name: api-port
containerPort: 9200
- name: node-port
containerPort: 9300
# 挂载数据到本地
volumeMounts:
- name: es-data
mountPath: /usr/share/elasticsearch/data
- name: es-log
mountPath: /usr/share/elasticsearch/logs
- name: es-log4j2
mountPath: /usr/share/elasticsearch/config/log4j2.properties
subPath: log4j2.properties
volumes:
- name: es-data
hostPath:
path: /var/lib/elasticsearch/data
- name: es-log
hostPath:
path: /var/log/elasticsearch/logs
- name: es-cert
configMap:
- name: es-log4j2
configMap:
name: log4j2.properties
items:
- key: log4j2.properties
path: log4j2.properties
mode: 0777
- apiVersion: v1
kind: Service
metadata:
name: elasticsearch
labels:
app: elasticsearch
spec:
clusterIP: None
ports:
- name: api-port
port: 9200
- name: node-port
port: 9300
selector:
app: elasticsearch
- apiVersion: v1
kind: Service
metadata:
name: es-svc
labels:
app: elasticsearch
spec:
type: NodePort
ports:
- name: es-api
port: 9200
targetPort: 9200
nodePort: 30200
- name: es-node
port: 9300
targetPort: 30300
selector:
app: elasticsearch
这里是在两个node上分别部署一个es节点。主要使用StatefulSet+headless service来实现通过域名进行集群服务发现的初始化。使用Statefulset可以使pod命名有规律。使用headless service可以实现通过{$podname}.{$servicename}来进行域名解析获取到pod的ip地址。这样便可以在配置的时候指定es节点的地址。 其他关于集群的配置很简单,直接看环境变量的配置也基本能明白,其他集群的配置可以查看
Important discovery and cluster formation settingsedit
对于es集群,我们是希望将es部署在不同的node上的,除了保证数据的高可用之外,es本身也是十分消耗资源的。但是如果不添加特定配置,k8s自动调度pod在哪台node上运行的话,可能会出现es节点运行在同一个node上。所以最好还是使用resources.requests字段来进行限制。而且一般es内存的配置,如我这里设置ES_JAVA_OPTS value = "-Xms16g -Xmx16g",意思是分配给es的对内存大小为16g。官方建议就是这个值的大小为物理内存大小的一半,而es底层是基于lucene的,另外一半最好留给lucene使用。
这里需要挂载出来两个路径,/usr/share/elasticsearch/data 和 /usr/share/elasticsearch/logs,分别是数据和日志的地址,最好是挂载出来将数据持久化。
不管关于日志的问题,这里的logs目录下记录的是gc的日志。而其他的日志信息如果要记录下来是需要另外配置的,主要是配置log4j2。详细配置信息可以查看官方介绍
Logging
logstach部署示例
kind: List
apiVersion: v1
items:
- apiVersion: v1
kind: ConfigMap
metadata:
name: logstash-conf
data:
logstash.conf: |
input {
beats {
port => "5044"
}
}
filter {
if [fields][doc_type] == 'syslog' {
json {
source => "message"
}
}
}
output {
if [fields][doc_type] == 'syslog'{
elasticsearch {
hosts => ["es-svc:9200"]
index => "syslog-%{+YYYY.MM.dd}"
}
}
}
- apiVersion: apps/v1
kind: Deployment
metadata:
name: elk-ls-rc
spec:
replicas: 1
selector:
matchLabels:
app: logstash
template:
metadata:
name: logstash
labels:
app: logstash
spec:
containers:
- image: ish2b/logstash:7.2.0
name: logstash
env:
volumeMounts:
- name: logstash-config
mountPath: /usr/share/logstash/pipeline
ports:
- name: http
containerPort: 5044
volumes:
- name: logstash-config
configMap:
name: logstash-conf
items:
- key: logstash.conf
path: logstash.conf
- apiVersion: v1
kind: Service
metadata:
name: elk-ls-nodeport
spec:
type: NodePort
ports:
- name: http
port: 5044
targetPort: 5044
nodePort: 30044
selector:
app: logstash
- apiVersion: v1
kind: Service
metadata:
name: logstash
spec:
clusterIP: None
ports:
- name: http
port: 5044
selector:
app: logstash
logstash的部署很简单,logstash的重点是配置logstash.conf文件。在这个文件中去部署输入,过滤和输出的信息,这里的输入是监听5044端口,也就是收集器需要将数据发送到该端口上。
而这里的filter部分,我们主要是用fileds doc_type来进行区分,可以将不同来源的数据进行对应的格式化,而这里的数据字符串为json格式的数据,所以就直接使用json插件进行文档格式化。因为最终存储在es的数据是以文档的形式存储的。
最后输出指定好es的服务地址,并且为该文档数据根据日期建立索引。
更多配置内容可以查看官方介绍
Logstash Configuration Examplesedit
filebeat部署示例
这里filebeat是同具体的服务一同部署在一个pod中的。
kind: List
apiVersion: v1
items:
- apiVersion: v1
kind: ConfigMap
metadata:
name: filebeat-config
data:
filebeat.yml: |
filebeat.inputs:
- type: log
paths:
- /home/log/*.log
scan_frequency: 10s
fields:
doc_type: syslog
output.logstash:
hosts: ["elk-ls-nodeport:5044"]
- apiVersion: apps/v1
kind: Deployment
metadata:
name: filebeat-test
spec:
replicas: 2
selector:
matchLabels:
app: filebeat
template:
metadata:
labels:
app: filebeat
namespace: sent
spec:
containers:
#filebeat
- image: docker.elastic.co/beats/filebeat:7.2.0
name: filebeat
args: [
"-c","/home/filebeat-config/filebeat.yml",
"-e",
]
volumeMounts:
- name: sys-log
mountPath: /home/log
- name: filebeat-config
mountPath: /home/filebeat-config
#sentlog服务
- image: ish2b/sentlog:latest
name: sentlog
volumeMounts:
- name: sys-log
mountPath: /sentlog
volumes:
#指定emptyDir:{}来共享数据卷
- name: sys-log
emptyDir: {}
- name: filebeat-config
configMap:
name: filebeat-config
首先配置好filebeat.yml配置文件,内容也很简单,配置输入的类型为log,日志文件的地址。关于地址有个点需要注意
比如有这样的地址配置:/home/log/*,/home/log/*/*
第一种是会收集/home/log目录下的所有日志文件,但是不会收集子目录里面的。第二种只会收集子目录里面的数据,log目录的日志数据是不会被收集的。
fields.doc_doc属性的作用就是可以在logstash中进行区分
还有一个参数can_frequency,表示 Filebeat检查指定用于收集的路径中的新数据的频率。默认10s.
最后输出指定为logstash(也可以直接输出到es)。
更多配置内容可以查看
Configure inputs
Configure the outputedit
接着这里我们开启两个pod,pod中有我们的服务sentlog和filebeat。通过共享数据卷的方式来使filebeat可以读取到sentlog服务产生的日志数据。
kibana部署示例
kind: List
apiVersion: v1
items:
- apiVersion: apps/v1
kind: Deployment
metadata:
name: elk-kb-rc
spec:
replicas: 1
selector:
matchLabels:
app: elk-kb
template:
metadata:
name: elk-kb-ct
labels:
app: elk-kb
spec:
containers:
- image: ish2b/kibana:7.2.0
name: kibana
env:
- name: ELASTICSEARCH_URL
value: "es-svc:9200"
- name: I18N_LOCALE
value: "zh-CN"
ports:
- name: kb-ct-port
containerPort: 5601
- apiVersion: v1
kind: Service
metadata:
name: elk-kb-svc
spec:
type: NodePort
ports:
- name: kb-svc-port
port: 5601
targetPort: 5601
nodePort: 30600
selector:
app: elk-kb
kibana的部署本身也很容易,也没有多少配置的内容,这里主要设置要es的服务地址就ok了。kibana还可以设置为中文版,但是I这个中文版翻译的并不是很好,也不全。
一般配置好运行之后,就可以看到在浏览器上查看了。
直接在kibana界面上进行一些基本的配置。
一开始进入discover界面是没有内容的
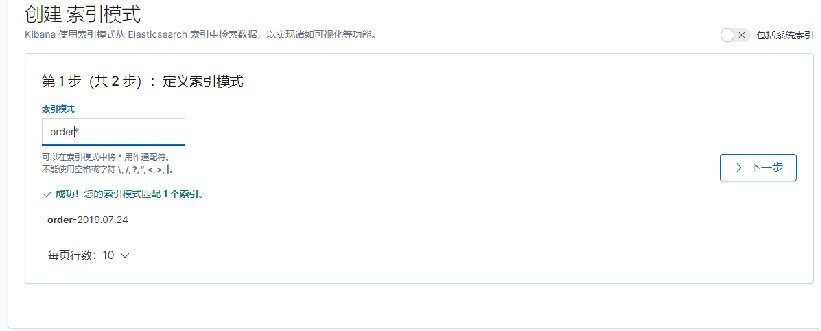
 我们需要配置索引模式。点击左上角进入管理,在kibana下创建索引模式
我们需要配置索引模式。点击左上角进入管理,在kibana下创建索引模式

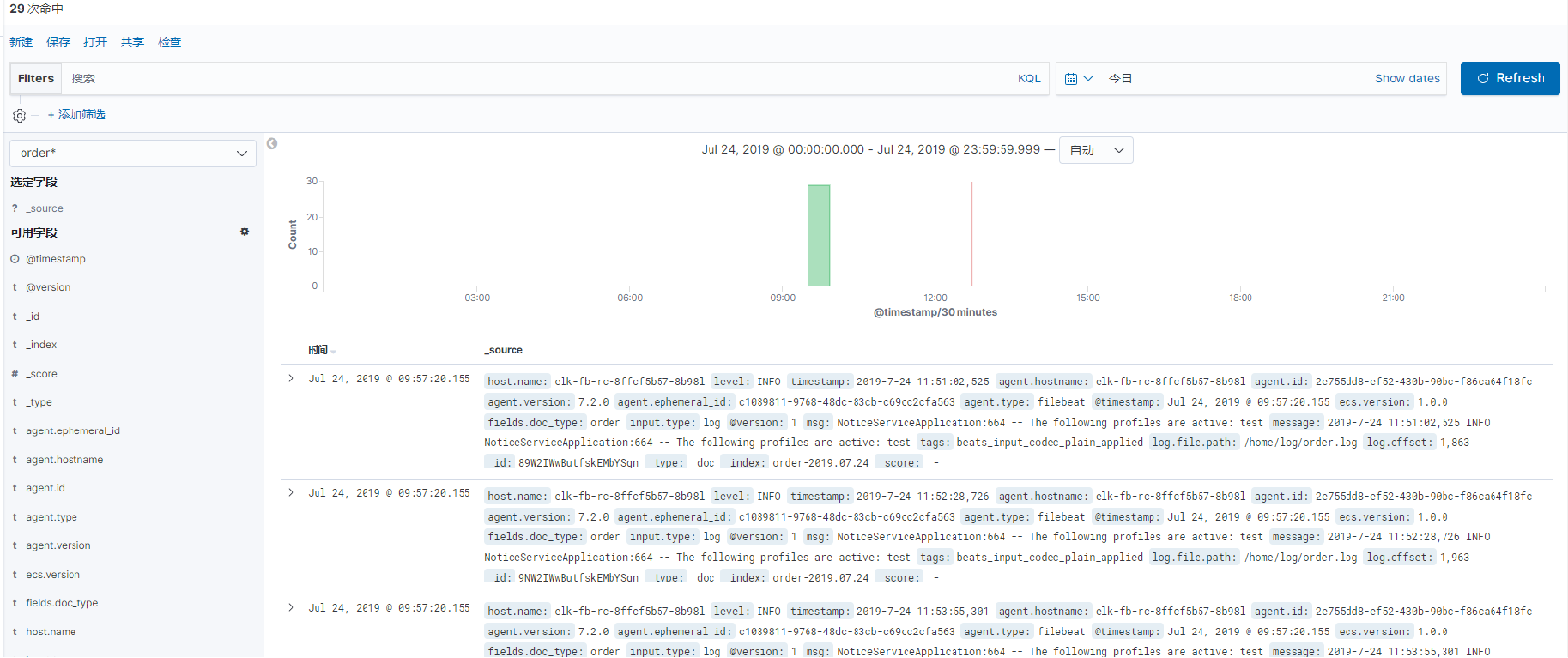
 最后回到discover界面便可以看到我们的日志数据了
最后回到discover界面便可以看到我们的日志数据了
到这里就是最基本的kibana的使用,然而kibana能呈现的远远不止这些。
我们可以创建可视化组件,如饼图,折线图等等来方便我们分析日志数据,并将他们整合到仪表盘,自定义可视化组件的布局。
在kibana中查看整个协议栈的健康状态。对索引进行管理,配置索引的生命周期策略,配置角色和用户来进行权限控制。对服务进行apm监控,并将数据传输给es,然后在kibana上呈现等等等等。更多的详细内容Kibana User Guide
可能遇到的问题及解决方法
遇到max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
执行sysctl -w vm.max_map_count=262144
因为Elasticsearch默认使用mmapfs目录存储索引。操作系统默认对mmap计数的限制可能太低,这可能导致内存异常。
“Caused by: java.io.IOException: failed to obtain lock on /usr/share/elasticsearch/data/nodes/0”,
可以使用chown -R ubuntu /var/lib/elasticsearch/