Kubernetes网络模型
- Ip是以Pod为单位分配的,一个Pod中的容器共享同一个Linux网络协议中,即端口共享,并且可以直接使用localhost来连接对方的端口。
- pod中的容器及应用程序看到的ip地址同外部看pod的Ip地址是相同的,即内外看到的pod的ip地址都是同一个。
kubernetes对集群网络有如下要求
- 所有容器可以不用NAT的方式下同别的容器通信
- 所有节点可以在不用NAT的方式下同所有容器通信,反之亦然
- 容器地址和别人看到的地址都是同一个地址(因为Docker容器内部服务开启的端口和地址会因为要映射而导致不同)
Docker网络基础
Linux内核虚拟化技术
1.网络命名空间
根据命名空间分隔不同的网络协议栈实例,使他们完全隔离,无法通信,从而实现在一个宿主机上虚拟多个不同的网络环境。Docker就是利用这一技术实现不同容器间网络的隔离。
2.Veth设备对
创建网络命名空间
ip netns add 2bnet
进入到命名空间中 (exit 退出)
in netns exec 2bnet bash
可以查看目前的命名空间
ip netns
查看网卡设备 (初始只有lo回环)
ip link show | ip addr

添加veth设备,veth可以用于连通两个不同命名空间网络栈
ip link add veth0 type veth peer name veth1
将veth1设置到2bnet这个命名空间中
ip link set veth1 netns 2bnet
配置网卡上的ip地址 并启动
ip netns exec 2bnet ip addr add 10.1.1.1/24 dev veth1
ip addr add 10.1.1.2/24 dev veth0
ip netns exec 2bnet ip link set dev veth1 up
ip link set dev veth0 up
这个时候就可以互相ping通了

查看路由表
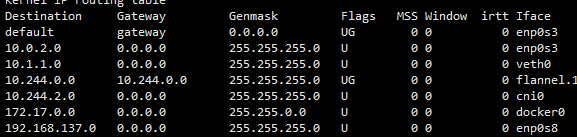
在Docker实现里面,就是将我们设置的veth1改名为eth0,虚拟为一个“本地网卡”。
3.网桥
同平时我们认识的网桥相似,都是转发局域网内数据,维护mac地址表。但是与单纯的不同,物理上的网桥要么转发,要么丢弃。而虚拟的网桥设备还可以送到上层。而且还有一个ip地址。他绑定网口,协议栈上层只能看到网桥,将数据包发送给网桥后即可,不关系内部细节,由网桥决定是发送给哪个设备。
Docker的网络实现
docker有四种网络模式,host模式、container模式、none模式、bridge模式。默认是bridge模式
bridge模式
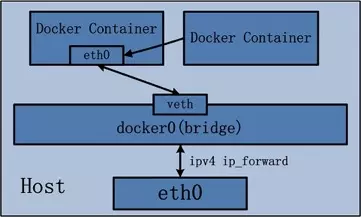
在该模式下,docker daemon会创建名为docker0的虚拟网桥。然后给这个私有网络空间分配一个子网。此时docker0也会分配到一个ip地址。当创建一个容器时,会创建一个虚拟的以太网设备对,容器内的一端命名为eth0,并分配一个ip地址(从属于同一个子网),另外一端关联到网桥上。
所以一般情况下主机ip,容器ip和docker0IP是不同的。外部无法看到内部docker的ip,结果就是内部容器可以通过docker0通信,但是外部却不行。
为了跨节点(主机)通信,就必须使用端口映射,将主机端口路由或代理到容器上。这样端口管理会复杂很多。 端口转发规则可以在iptable上查看到,简单的说就是将进入到该端口的数据包的目标地址和端口更改为容器上的地址和端口,然后再由docker0去转发。
局限性就是考虑多主机互联的网络解决方案。
kubernetes的网络实现
kubernetes网络实现解决以下场景
- 容器到容器之间的直接通信
- 抽象的Pod到Pod之间的通信
- Pod到Service之间的通信
- 集群外部与内部组件之间的通信
容器到容器之间的通信
同一个pod中的容器是共享命名空间的,所以可以直接使用localhost+端口去访问。Pod中除了提供服务的容器外,还会有一个pause容器,其他的容器的网络模式都使用container模式连接到这个pause容器上,这样他们就共享了同一网络命名空间。自然他们也共享同一个ip
使用一个pause的好处是,如果启动第一个容器,而这个容器死了,那么连接他的容器也跟着一起完蛋。启动一个基础容器,所有容器去连接到它上面会更容易一些。而且多个容器启动的话,将他们连接起来也不是那么容易的。
Pod之间的通信
同一个Node内的Pod之间的通信
Pod之间通过Veth连接到同一个网桥上,故他们是属于同一个网段内的,所以可以直接使用对方的ip访问。pod中的默认路由都是docker0地址。所以发出去的网络请求都是经由docker0转发。
不同Node的Pod之间的通信
因为pod是与docker0处于同一个网段内的。而docker0又与宿主机网卡是两个不同的网段。而要实现不同Node之间的通信又必须经过宿主机的网卡。
而且这些pod之间的ip地址应该是平面和直达的,换句话说,他们不能有冲突。
所有要实现就必须解决以下两个问题
- 整个集群中podip的分配要有规划,不能冲突。
- 找到一种方法,将Pod的ip所在的Node的ip关联起来,通过这个关联让pod之间可以相互访问。
1.手工配或者使用flannel网络增强开源软件来管理分配
2.也是使用各种开源组件来实现;如果有自己的虚拟机环境,也可以自己配置,在路由表中添加对应的docker0网段所在宿主机的ip,将发送给该网段的请求路由到该主机上(所以猜想各种组件最终要实现的效果应该也同这个类似)
# 10.1.20.0就是docker0所在的网段,gw就是目标网络了
route add -net 10.1.20.0 netmask 255.255.255.0 gw 192.168.1.130
serive和kube-proxy
服务可以隐藏后部的Pod,并将pod作为一个集群,统一提供服务,实现负载均衡。实现这一功能的关键是kube-proxy。kube-proxy 运行在每个节点上,监听 API Server 中服务对象的变化,通过管理 iptables 来实现网络的转发。当我们访问一个clusterIP时,即service分配到的虚拟ip,可以使用iptables-save查看转发规则
# service信息
service/es-svc NodePort 10.100.79.190 <none> 9200:30200/TCP,9300:30070/TCP 26h
#以下都iptables得输出信息
-A OUTPUT -m comment --comment "kubernetes service portals" -j KUBE-SERVICES
-A KUBE-SERVICES -d 10.100.79.190/32 -p tcp -m comment --comment "default/es-svc:es-api cluster IP" -m tcp --dport 9200 -j KUBE-SVC-N6HHKJLNJXWLBPKB
#可以看到,他是随机从三个节点中去访问的
-A KUBE-SVC-N6HHKJLNJXWLBPKB -m statistic --mode random --probability 0.33332999982 -j KUBE-SEP-BVM2FVVPRW75VUNG
-A KUBE-SVC-N6HHKJLNJXWLBPKB -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-6HJGYMMQWJRCIELD
-A KUBE-SVC-N6HHKJLNJXWLBPKB -j KUBE-SEP-WW3IJWYVBS5P5N4M
-A KUBE-SEP-BVM2FVVPRW75VUNG -s 10.244.0.28/32 -j KUBE-MARK-MASQ
-A KUBE-SEP-BVM2FVVPRW75VUNG -p tcp -m tcp -j DNAT --to-destination 10.244.0.28:9200
-A KUBE-SEP-6HJGYMMQWJRCIELD -s 10.244.0.29/32 -j KUBE-MARK-MASQ
-A KUBE-SEP-6HJGYMMQWJRCIELD -p tcp -m tcp -j DNAT --to-destination 10.244.0.29:9200
cni与flannel
Container Network Interface
最早是由CoreOS发起的容器网络规范,是Kubernetes网络插件的基础。其基本思想为:Container Runtime在创建容器时,先创建好network namespace,然后调用CNI插件为这个netns配置网络,其后再启动容器内的进程。
CNI插件包括两部分:
- CNI Plugin负责给容器配置网络,它包括两个基本的接口
- 配置网络: AddNetwork(net NetworkConfig, rt RuntimeConf) (types.Result, error)
- 清理网络: DelNetwork(net NetworkConfig, rt RuntimeConf) error
- IPAM Plugin负责
给容器分配IP地址,主要实现包括host-local和dhcp。
flannel
Flannel通过给每台宿主机分配一个子网的方式为容器提供虚拟网络,它基于Linux TUN/TAP,使用UDP封装IP包来创建overlay网络,并借助etcd维护网络的分配情况。
主要解决一下两个问题
- 如果分配ip地址
- 如何跨节点主机实现pod直接的互相通信
首先第一点,如何分配ip地址。由于整个集群的信息都会存储在etcd上,所以自然关于每个node上的子网信息也从etcd获取,flannel便可根据etcd中的信息分配ip地址而不产生冲突,
实现在在不同node上的pod直接互通。首先明确fannel为node之间维护一个Overlay(覆盖网络)网络来拼接成一个大网来实现互联的。网络拓补看下图
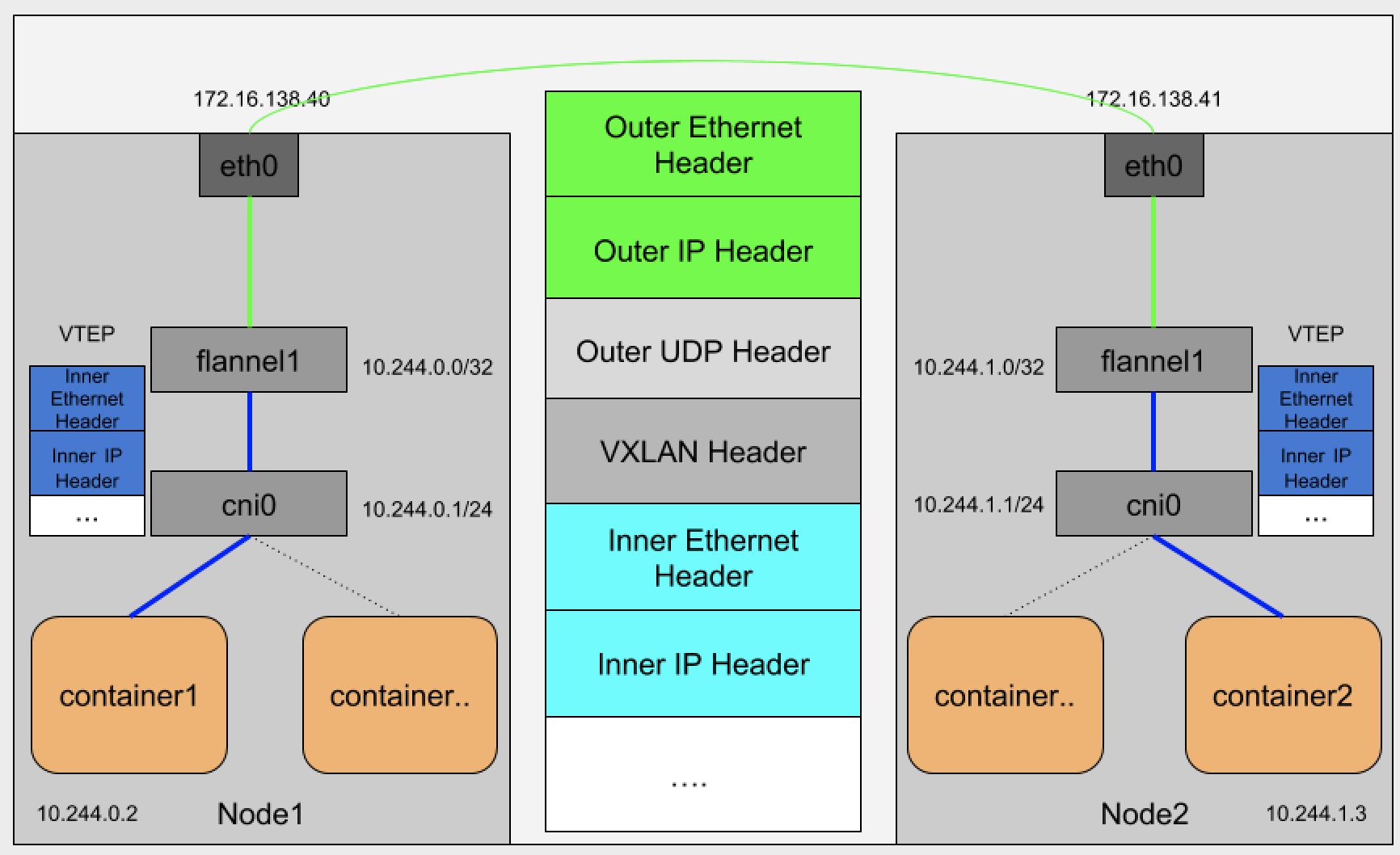
cni0
可以简单的类比为docker0,他的作用和docker0差不多,都是一个网桥,而且端口连接着容器内的eth0,只是该cni0的网段是由falnnel分配的,如这里是10.244.0.0/24。可以在容器中和node中使用
ip addr 和 route 来查看路由表信息和设备信息。
flannel1
这里就是整个网络通信的关键了,此时查看路由表信息,会看到10.244.1.0/24 对应的网关地址为10.244.1.0/24 设备为flannel.1,表示数据包交由给本机的flannel1设备,网关为目的node的flannel1,所以本机的flannel1在接收到这个数据包后会查询目的网关的mac地址。
这里就有区别于普通的查询方式,这里并不是使用arp协议去寻找,而是由linux kernel引发一个”L3 MISS”事件并将arp请求发到用户空间的flanned程序。flanned程序收到”L3 MISS”内核事件以及arp请求后,并不会向外网发送arp request,而是尝试从etcd查找该地址匹配的子网的vtep信息。可以使用
arp -a | grep flannel.1 查看对应ip到mac的记录。
那么完成这一步查询之后,我们看上图中的数据头部,此时的Inner IP Header和Inner Ethernet Header就是对于的IP地址和Mac地址。但是现在只是fannle这一层的网络协议到达第二层,而最终我们还是要经过实际的物理链接去通信的。这里在给他加上VXLAN Header头部做区分。
那么现在的问题就是,如何知道我们要去的mac地址对应的是哪一台node呢?即mac到node ip的映射。kernel需要查看node上的fdb(forwarding database)以获得他们之间的映射关系,如果fdb中没有这个信息,那么kernel会向用户空间的flanned程序发起”L2 MISS”事件。flanneld收到该事件后,会查询etcd,获取该mac地址对应的node的”Public IP“,并将信息注册到fdb中。可以使用命令bridge fdb show 来查看。
那么这个时候通过fdb寻找到目标node的ip地址,就可以在数据包头部带上目的ip,就是Outer Ip header。并通过arp协议去寻找目的ip的mac地址。最终通过node上的etho0网卡设备发送数据。
接收方就是逆过程,目的主机etho0收到报文后会拆封并识别出是vxlan包,于是将包转给flannel1,flannel1在将数据包转给cni0,最终交付到目的pod手上。
参考
https://tonybai.com/2017/01/17/understanding-flannel-network-for-kubernetes/ https://www.cnblogs.com/xzkzzz/p/9936467.html https://www.cnblogs.com/goldsunshine/p/10740928.html