映射
映射是定义文档及其包含的字段的存储和索引方式的过程。每个索引都有一个映射类型,他决定了文档将如何被索引。
搜索
精确搜索(exact search)
需要输入完整的值才能搜索得到结果,在建立倒排索引的时候,是将整个值作为一个关键字建立到倒排索引中的;
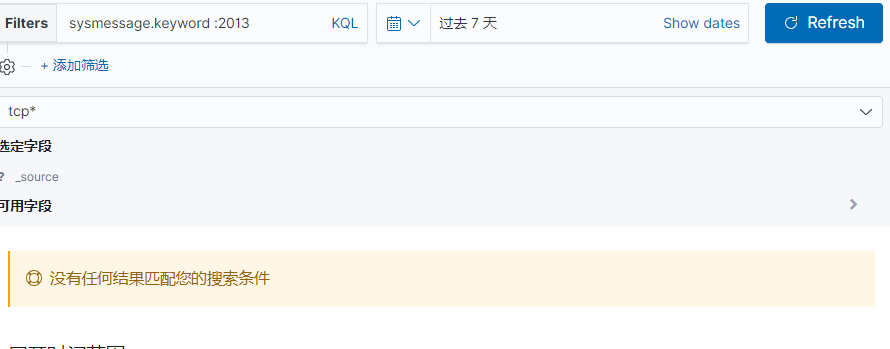
全文搜索(full-text search)
当你进行搜素的时候,会对值进行拆分词语后进行匹配,所以可能通过缩写,大小写,同义词等进行匹配。在建立索引时,会先经历各种的处理,分词,时态转换,同义词转换,大小写转换然后才建立到倒排索引中。
 在没有指定对哪一字段进行搜索时,即对all_fileds进行搜索,会将所有字段的值拼接起来然后分词。
在没有指定对哪一字段进行搜索时,即对all_fileds进行搜索,会将所有字段的值拼接起来然后分词。
映射类型
元字段(meta-fields)
每个文档都具有与之关联得元字段,例如_index,_type,_id等等。在创建映射类型时,可以定制其中一些元字段的行为。
身份元字段
- _index:表示该文档属于哪个索引
- _type:表示文档得映射类型
- _id:文档id
文档源元字段
- _source: 表示文档主体的原始JSON。
索引元字段
- _field_names:文档中包含非空值的所有字段。
- _ignored:在索引时由于ignore_malformed而被忽略的文档中的所有字段。
路由元字段
- _routing: 将文档路由到特定碎片的自定义路由值。
其他元字段
- _meta:特定于应用程序的元数据。
字段或者属性
映射类型包含与文档相关的字段或属性列表。
字段数据类型
一般es会自动根据值来进行动态映射,通过json中基本数据类型进行猜测。
常见的类型如text,keyword, date, long, double, boolean or ip。
keyword类型用于索引结构化内容(如电子邮件地址、主机名、状态码、邮政编码或标记)的字段。一般用于需要过滤排序和聚合的字段。需要精确搜索。
全文搜索使用text字段更多类型介绍
fields参数
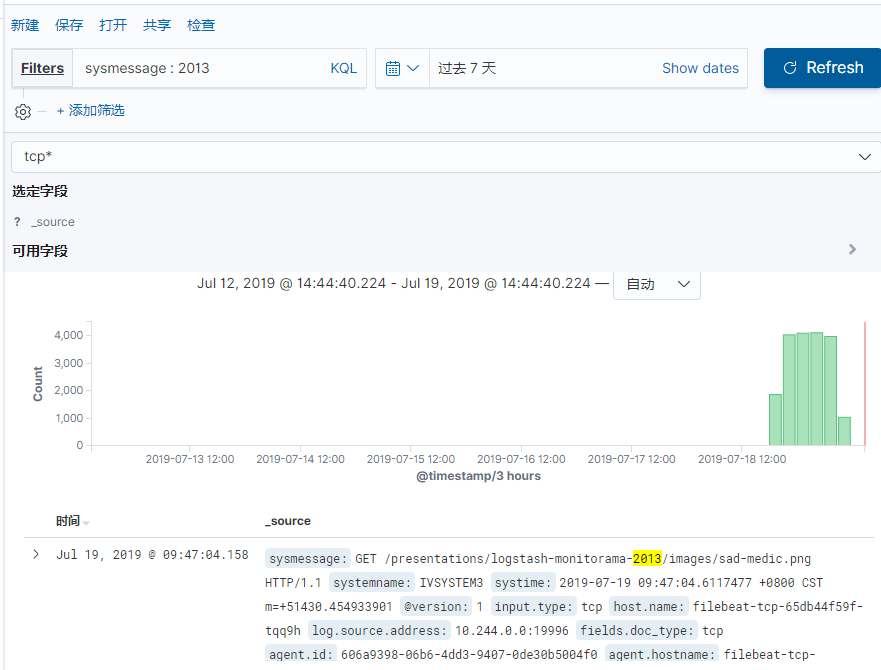
这里要特别说一个fields参数。通常我们需要对某个字段进行搜索时,可能除了需要满足全文搜素外,还需要对进行排序或者聚合。这样就要求这个字段要同时属于keyword类型和text类型。例如
"sysmessage": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
这里的message字段除了text类型外,还额外附加了keyword类型。这样sysmessage字段即可以全文搜索,也可以精确搜索了。如上面搜索sysmessage时所示。
分词器(Analyzers)
就是对根据选择的分词器类型对值串进行分词并添加到倒排索引中以便查询。类别详情看官方文档。Analyzers
例如以下这段句子
“The QUICK brown foxes jumped over the lazy dog!”
使用english分词器,将分解为
[ quick, brown, fox, jump, over, lazi, dog ]
映射爆炸
当一个索引的映射过多时,可能会导致内存不足和难以恢复的错误。一般可能出现在使用动态映射的情况,每次添加文档都有新的字段添加到映射中,随着文档数量的增加,映射也会更着变大,这就有可能导致映射爆炸的问题。可以通过设置一些参数来限制字段映射的数量。参数详情
已经存在的字段映射无法更新
更改映射将意味着已经索引的文档无效。相反,应该使用正确的映射创建一个新索引,并将数据重新索引到该索引中。