PMG介绍
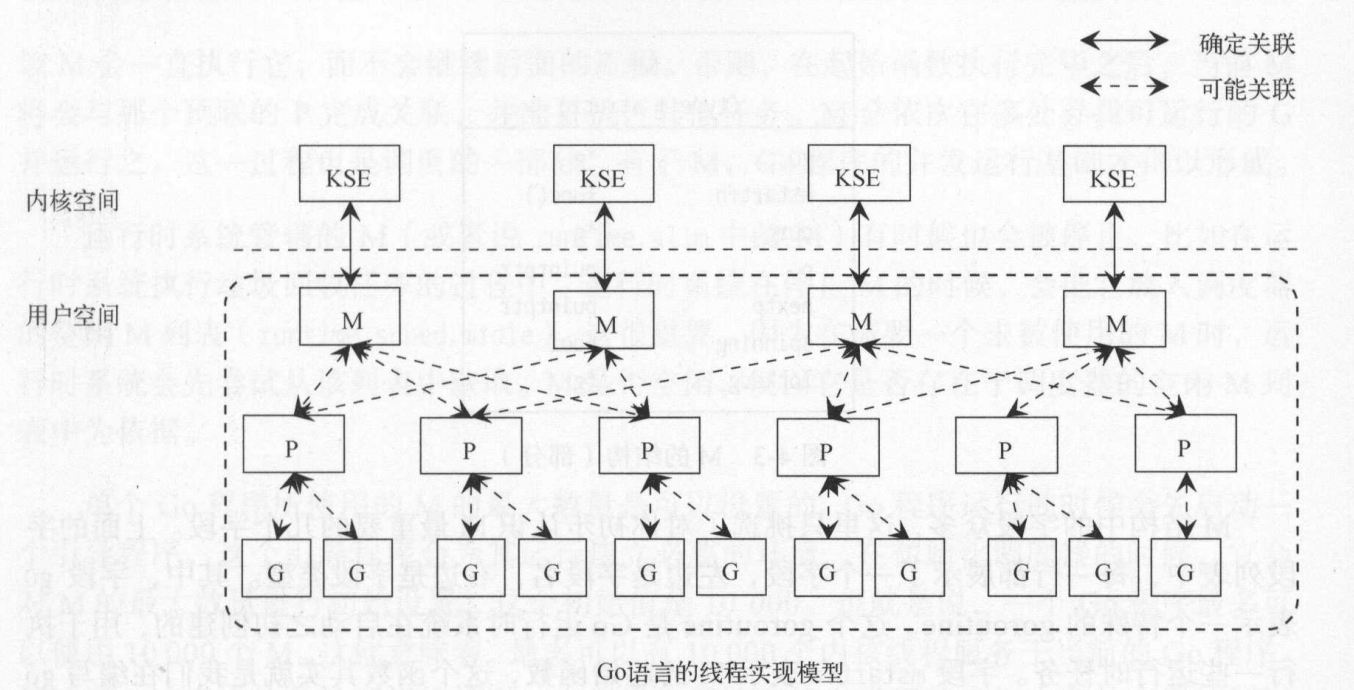
- G: .表示Goroutine,每个Goroutine对应一个G结构体,G存储Goroutine的运行堆栈、状态以及任务函数,可重用。G并非执行体,每个G需要绑定到P才能被调度执行。
- P: Processor,表示逻辑处理器, 对G来说,P相当于CPU核,G只有绑定到P(在P的local runq中)才能被调度。对M来说,P提供了相关的执行环境(Context),如内存分配状态(mcache),任务队列(G)等,P的数量决定了系统内最大可并行的G的数量(前提:物理CPU核数 >= P的数量),P的数量由用户设置的GOMAXPROCS决定,但是不论GOMAXPROCS设置为多大,P的数量最大为256。
- M: Machine,OS线程抽象,代表着真正执行计算的资源,在绑定有效的P后,进入schedule循环;而schedule循环的机制大致是从Global队列、P的Local队列以及wait队列中获取G,切换到G的执行栈上并执行G的函数,调用goexit做清理工作并回到M,如此反复。M并不保留G状态,这是G可以跨M调度的基础,M的数量是不定的,由Go Runtime调整,为了防止创建过多OS线程导致系统调度不过来,目前默认最大限制为10000个。
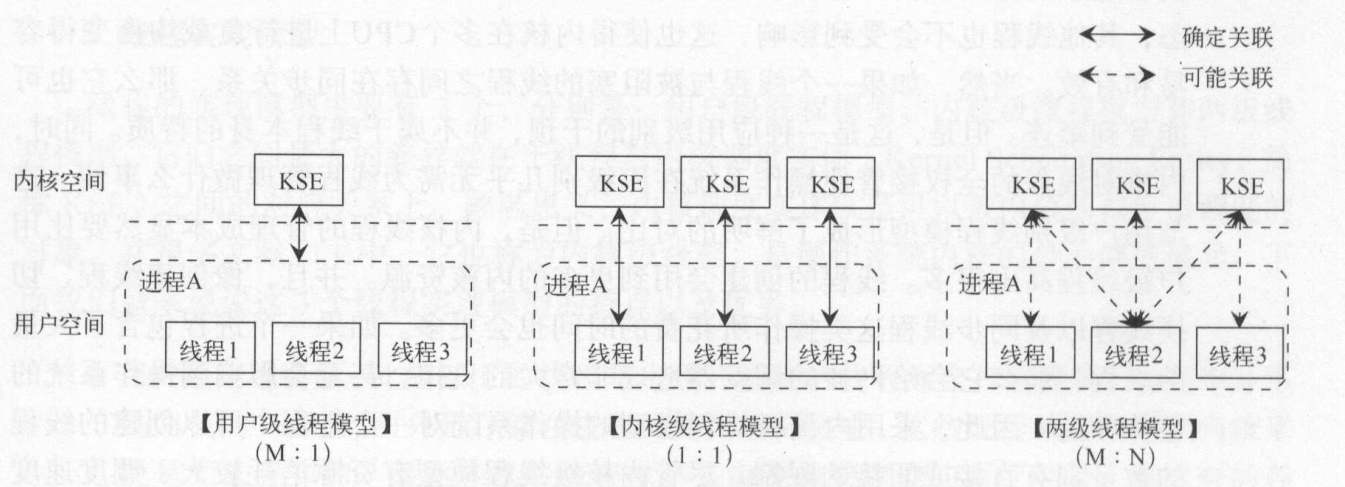
两级线程模型
用户级线程模型:用户自定义调度算法,系统无法感知用户级别的线程
内核级系统模型:线程交由系统内核调度,能够利用多核实现并行
两级线程模型:多对多的线程实现,即创建多个内核级线程,然后通过这些内核级线程对应用级线程进程调度。
调度
有 4 种事件会引起 Go 程序触发调度。这不意味着每次事件都会触发调度。Go 调度器会自己找合适的机会。
- 使用关键字 go
- 垃圾回收
- 系统调用
- 同步互斥操作,也就是 Lock(),Unlock() 等
你可以认为 Goroutine 是应用级别的线程,它在很多方面跟系统的线程是相似的。就像系统线程不断的在一个 core 上做上下文切换一样,Goroutine 不断的在 M 上做上下文切换。
把系统层面的 IO/阻塞 操作转换成了 CPU密集 操作来最大化每个 CPU 的能力。
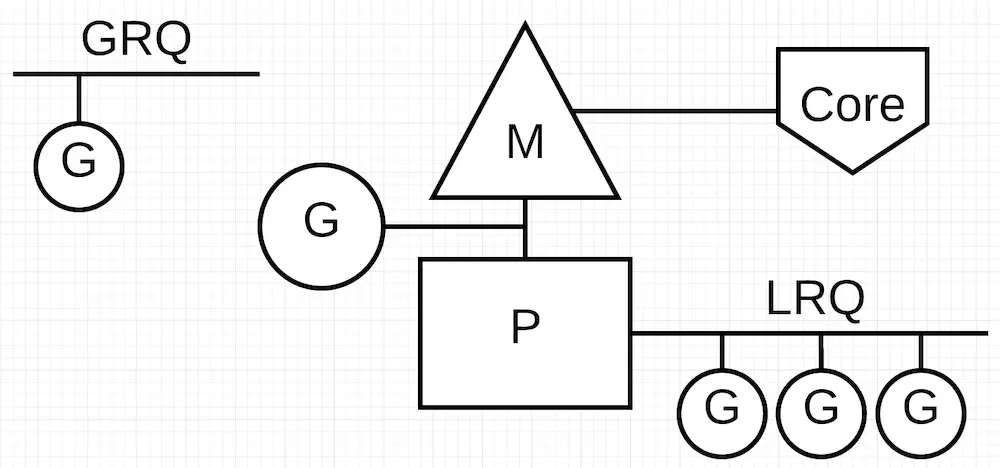
GO可以不需要使用到线程池或者说是协程池,这是由他的调度模型决定的,当我们新创建一个Goroutine的时候,他会现在本地p的自由g列表中寻找可用的g,如果没有再从其他的p或者调度器的全局自由g哪里获取,都没有的情况下才会去创建一个g,得到g之后进行一些初始化然后就放入到当前p的可运行g队列中,等到被运行;
如果当前p已经有一个m与他关联,那么他就会被放入到这个M中执行;如果没有M,那么P会尝试去空闲的M列表中寻找空闲的M来执行G;当g运行完毕之后,他就会被放入当前g的自由g队列,以备后续使用,而当前P会继续寻找可运行的g来执行,如果当前p没有,会先从全局g队列中获取,全局g队列为空,才会执行work stealing那么他会随机选一个其他的P去获取一半的可运行g来执行;
通过以上大致流程的分析,就可以知道Go里面的g和m都是复用的,他不会说每次需要一个线程或者协程就直接去创建一个,只有当现在p需要一个m来执行,但是到处都找不到空闲m的时候才会创建,如果G没有执行一些需要锁定m的阻塞操作的话,m大部分时间都会和一个m关联在一起,保持繁忙的状态,而且这里说到p会去窃取其他p的g,这么做就可以保证当前的m不会因为没有g运行而被系统换下,让他保持繁忙,从而避免不必要的切换的开销;