压缩列表的结构如下图

他是一系列特殊编码的连续内存块组成的顺序型数据结构,即将一系列数据与其编码信息存储在一块物理上连续的内存空间上,但是逻辑上确是分作多个部分,其目的是在一定可控的时间复杂度读条件下尽可能的减少不必要的内存开销,从而达到节省内存的效果;
当列表键和哈希键只包含少量的项并且每个列表项要么是比较小的整数值或者比较短的字符串时,就会使用压缩列表;
节点结构如下
typedef struct zlentry {
// 前一个节点的长度
unsigned int prevrawlensize;
// 前一个节点编码所需长度
unsigned int prevrawlen;
// 当前节点长度
unsigned int lensize;
// 当前节点编码所需长度
unsigned int len;
// 头的大小
unsigned int headersize;
// 编码类型
unsigned char encoding;
// 字节指针
unsigned char *p;
} zlentry;
每个节点都有可能存储的是一个字节数组 或者一个整数值
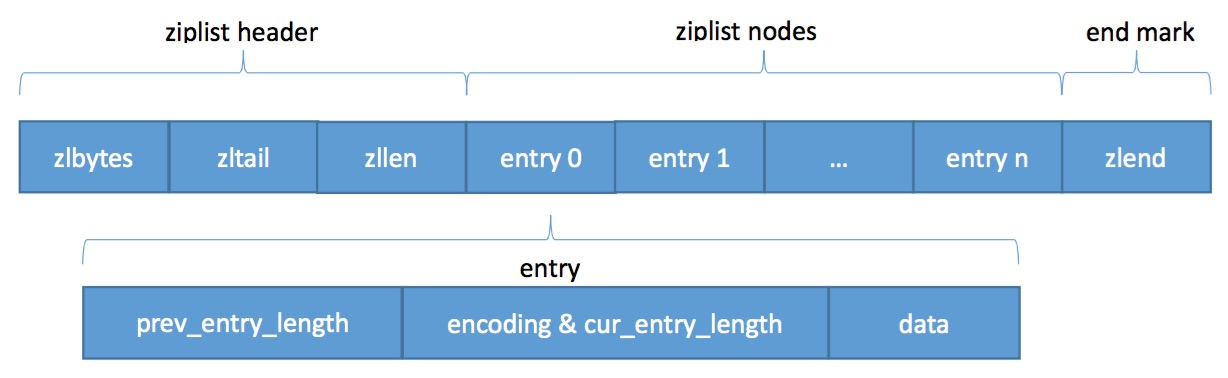
节点中的内容大致分为三个部分
- previous_entry_length :前一个节点的长度,
通过该值可以实现向前遍历;该字段的大小为1字节或者5字节,但前一个节点的大小小于254字节时,该字段为1字节,大于为5字节; -
encoding :记录data的所保存数据的类型和长度;
- data:保存节点值得内容;
encoding
字节数组编码,该字段长度可以为125字节;
- 00bbbbbb 共 1 字节,表示长度小于等于 63 字节的字符数组
- 01bbbbbb xxxxxxxx 共 2 字节,表示长度小于等于 16 383 字节的字符数组
- 10__ aaaaaaaa bbbbbbbb cccccccc dddddddd 共 5 字节,表示长度小于等于 4 294 967 295 字节的字符数组
整数编码
- 11000000 共 1 字节,代表 content 保存 int16_t 类型的整数
- 11010000 共 1 字节,代表 content 保存 int32_t 类型的整数
- 11100000 共 1 字节,代表 content 保存 int64_t 类型的整数
- 11110000 共 1 字节,代表 content 保存 24 位有符号整数
- 11111110 共 1 字节,代表 content 保存 8 位有符号整数
- 1111xxxx 共 1 字节,使用这一编码的的节点 content 不保存属性,因为 xxxx 已经能代表 0 ~ 12 的值,所以不需要保存在 content 属性里面
应用分析
压缩列表的新增、删除的操作平均时间复杂度为O(N),随着N的增大,时间必然会增加;然而压缩列表利用巧妙的编码技术存储内容尽可能的减少不必要的内存开销,节省了链表指针的存储空间开销,最好情况下只需要两个字节,这一点充分体现了“压缩”的特点。
但是他存在一个最大的问题就是“连锁更新”,因为每一个节点都保存着上一个节点长度,如果此时该字段为1字节,现在在他前面插入一个新的节点,长度大于254字节,那么该字段就需要扩展为5字节,如果该节点本身为254字节,扩展后本身超过了254字节,那么他的下一个节点的previous_entry_length字段也要扩展,如果后续的都是相同的情况,那么插入一个新节点的最坏情况就会是O(n);删除也同样可能导致该问题;